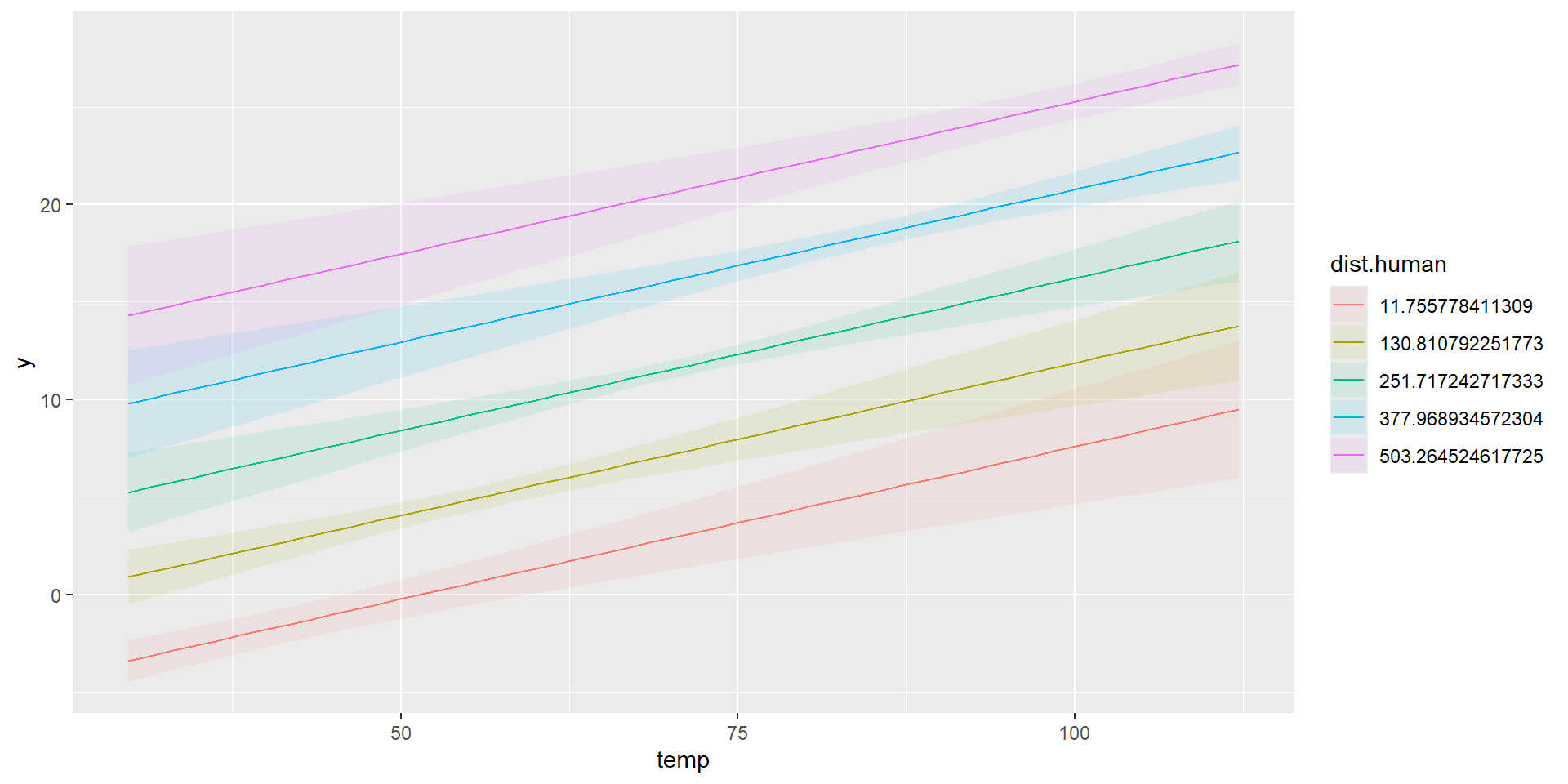
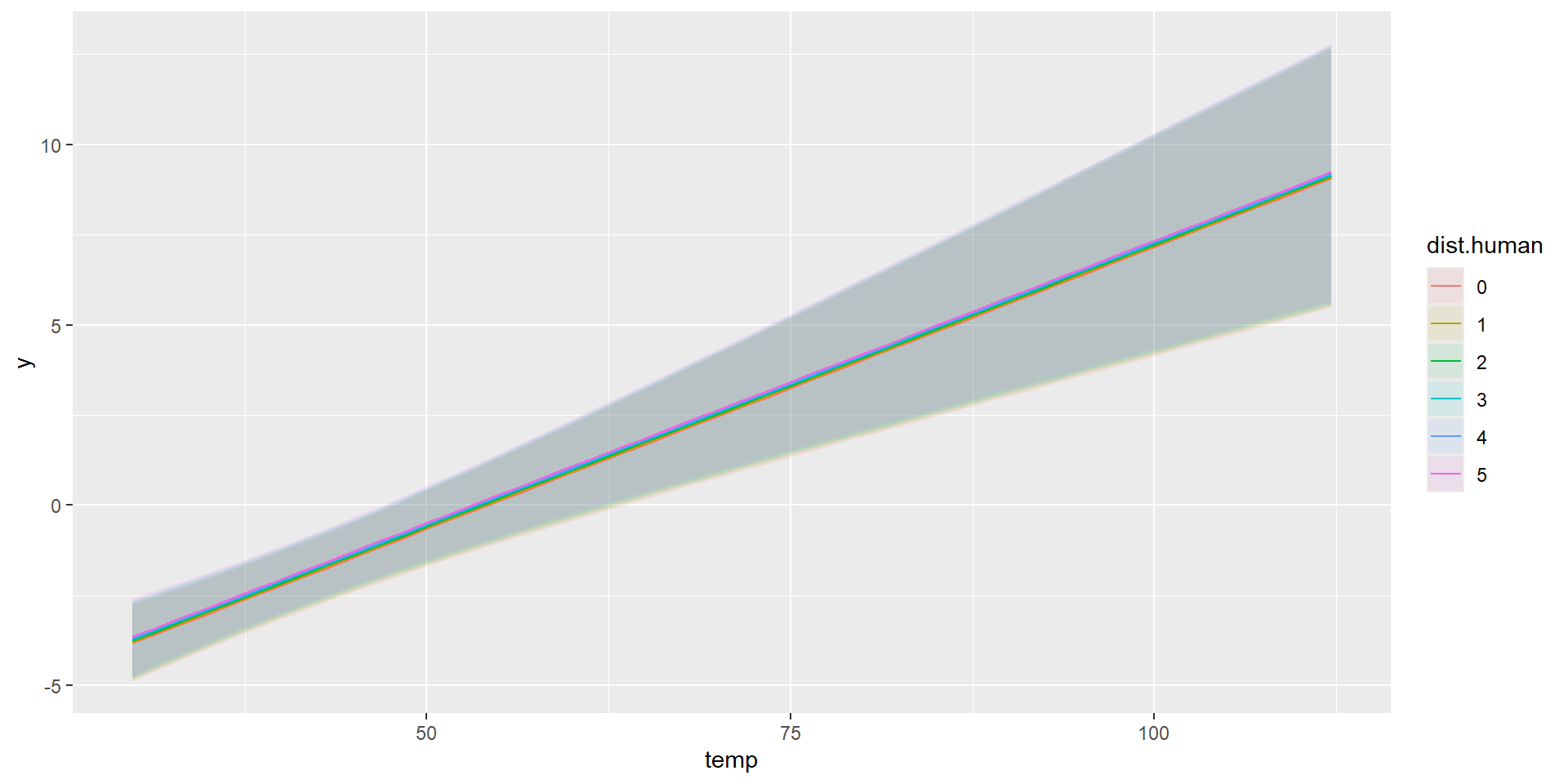
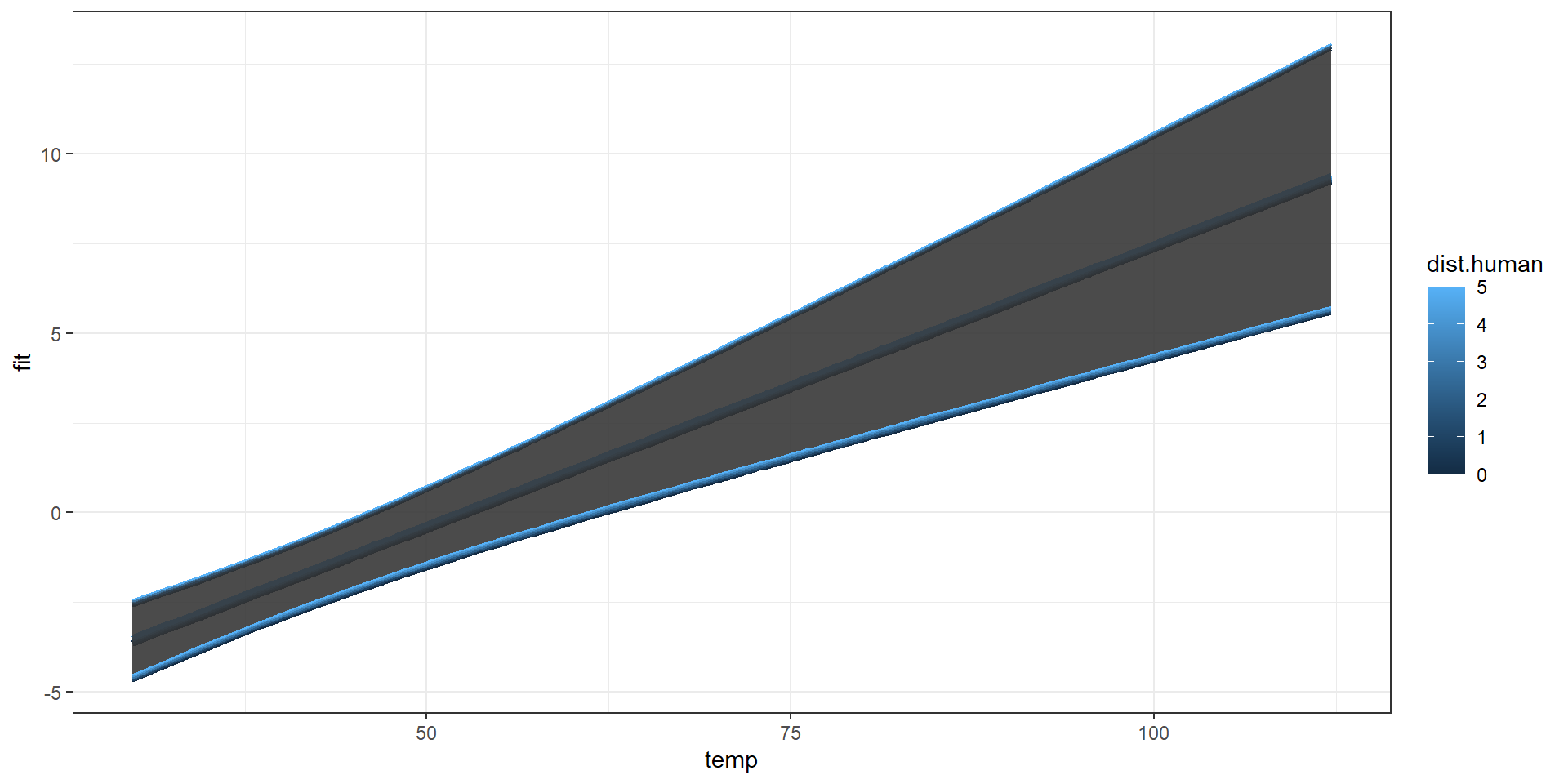
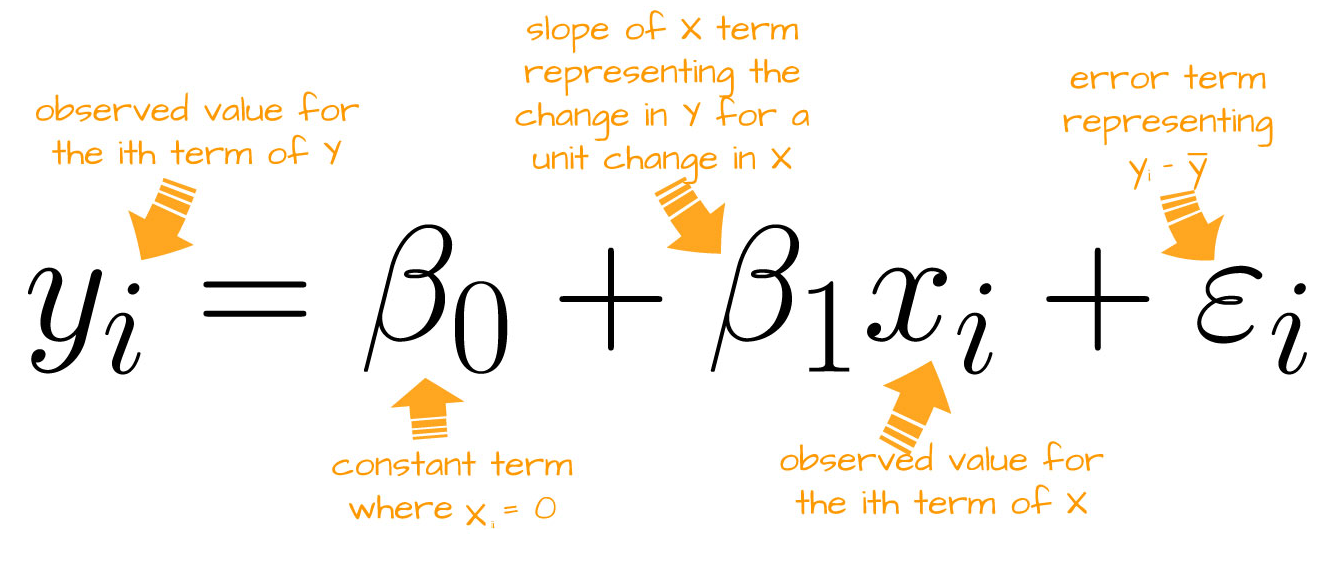Correlation(\(\epsilon_{i}\),\(\epsilon_{j}\)) = 0, \(\forall\) pairs of \(i\) and \(j\)
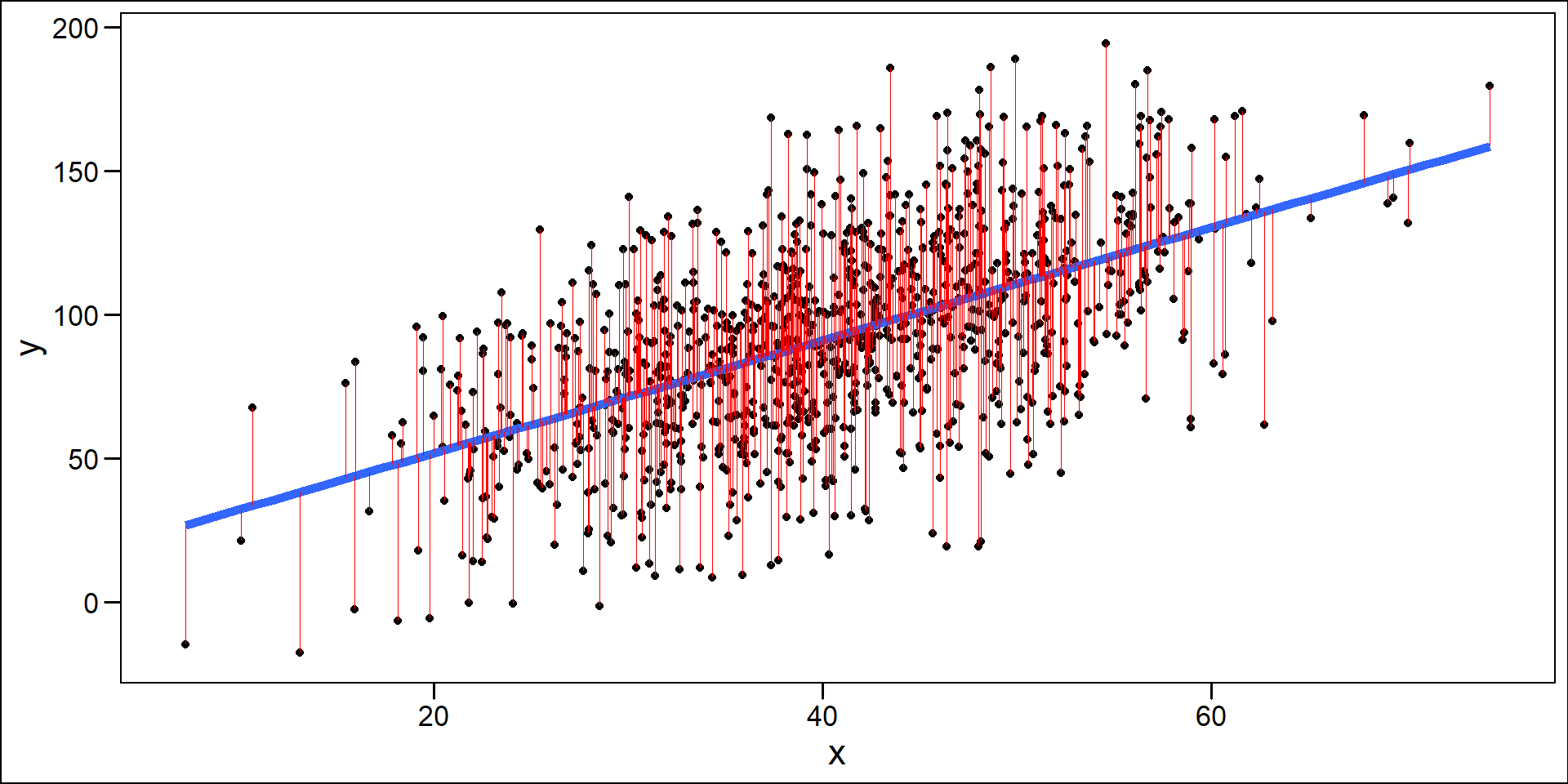
This means that knowing how far observation \(i\) will be from the true regression line tells us nothing about how far observation \(j\) will be from the regression line.
Assumptions
Homogeniety of the variance
var(\(\epsilon_{i}\)) = \(\sigma^2\)
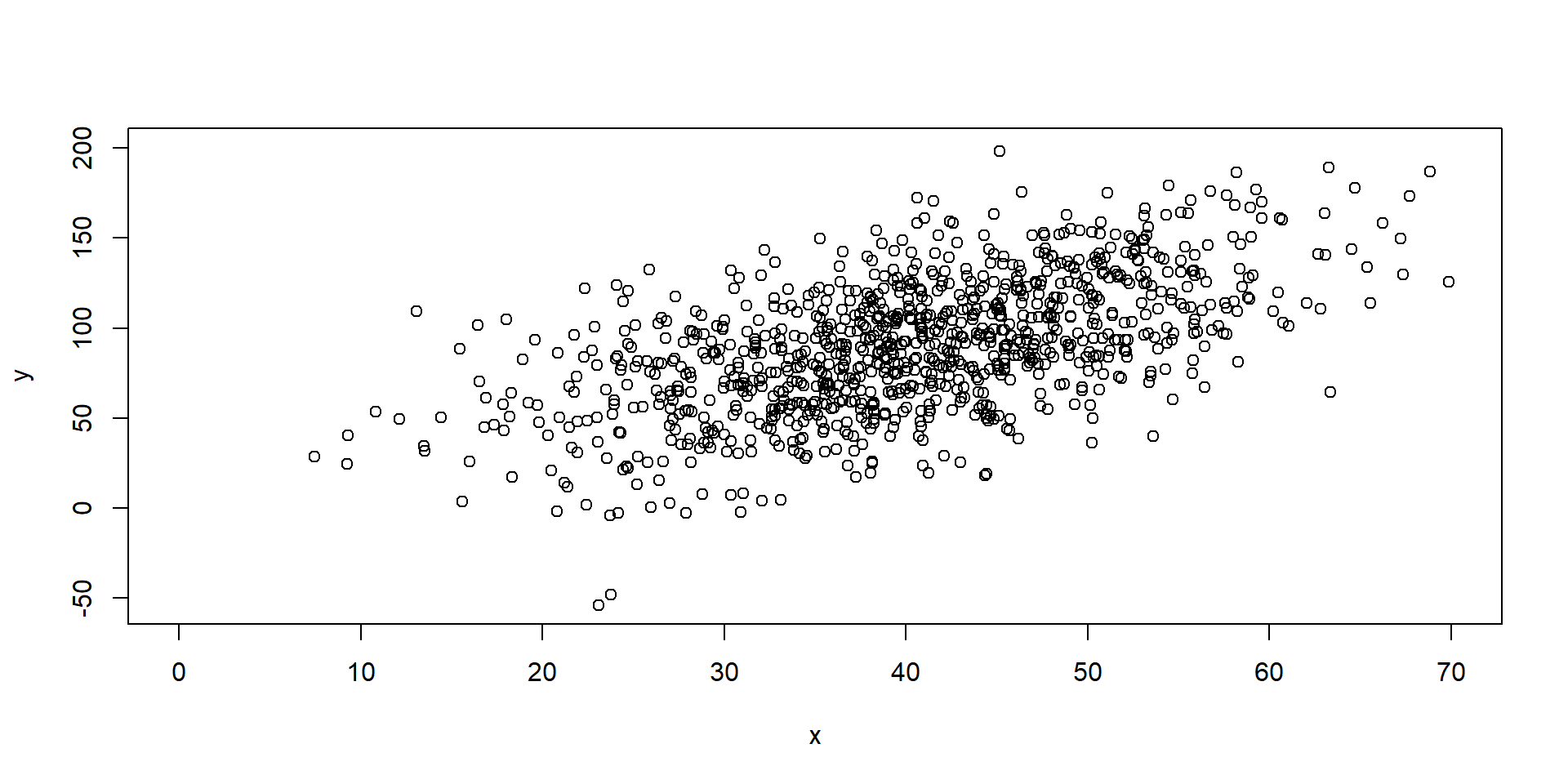
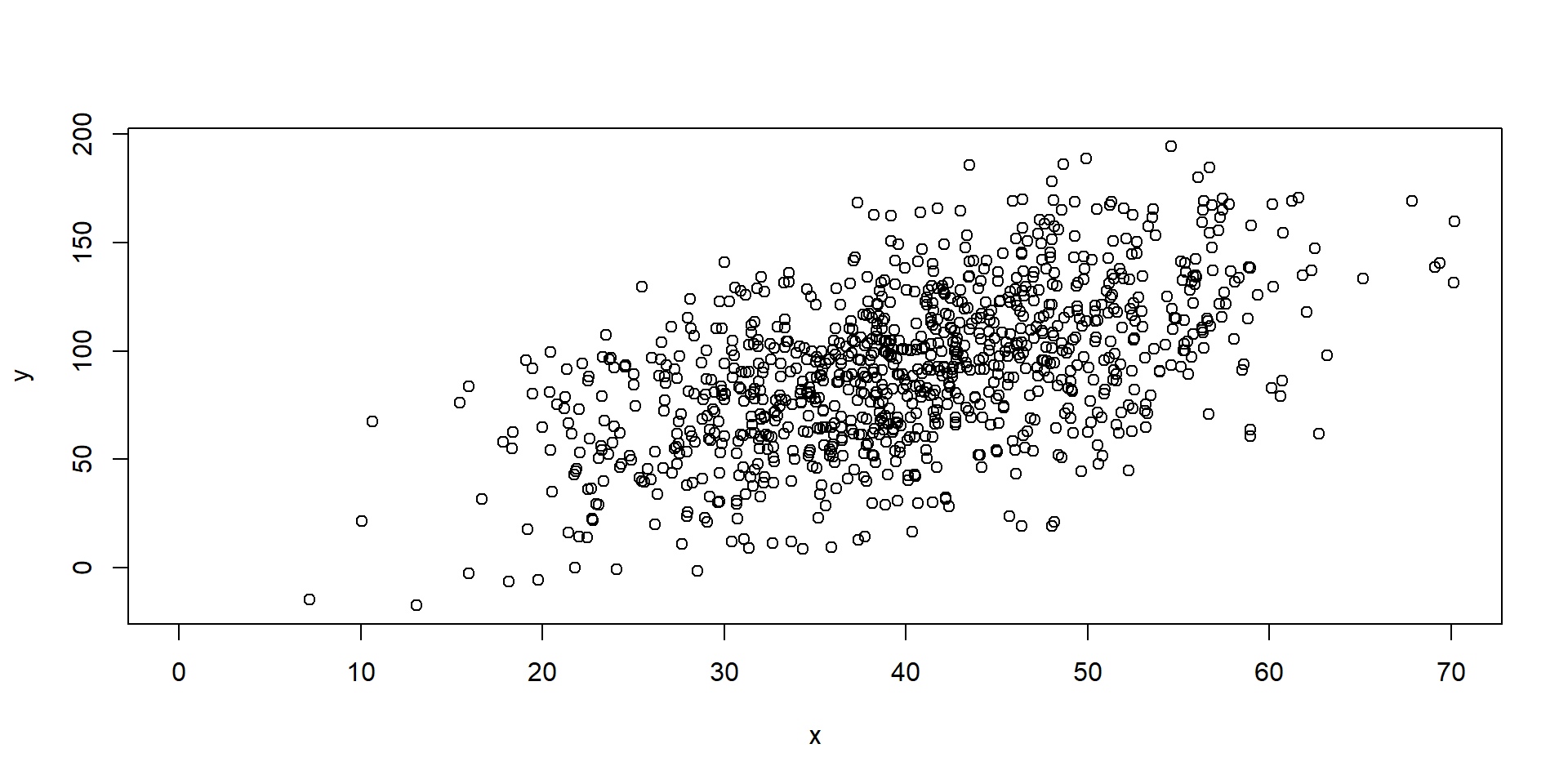
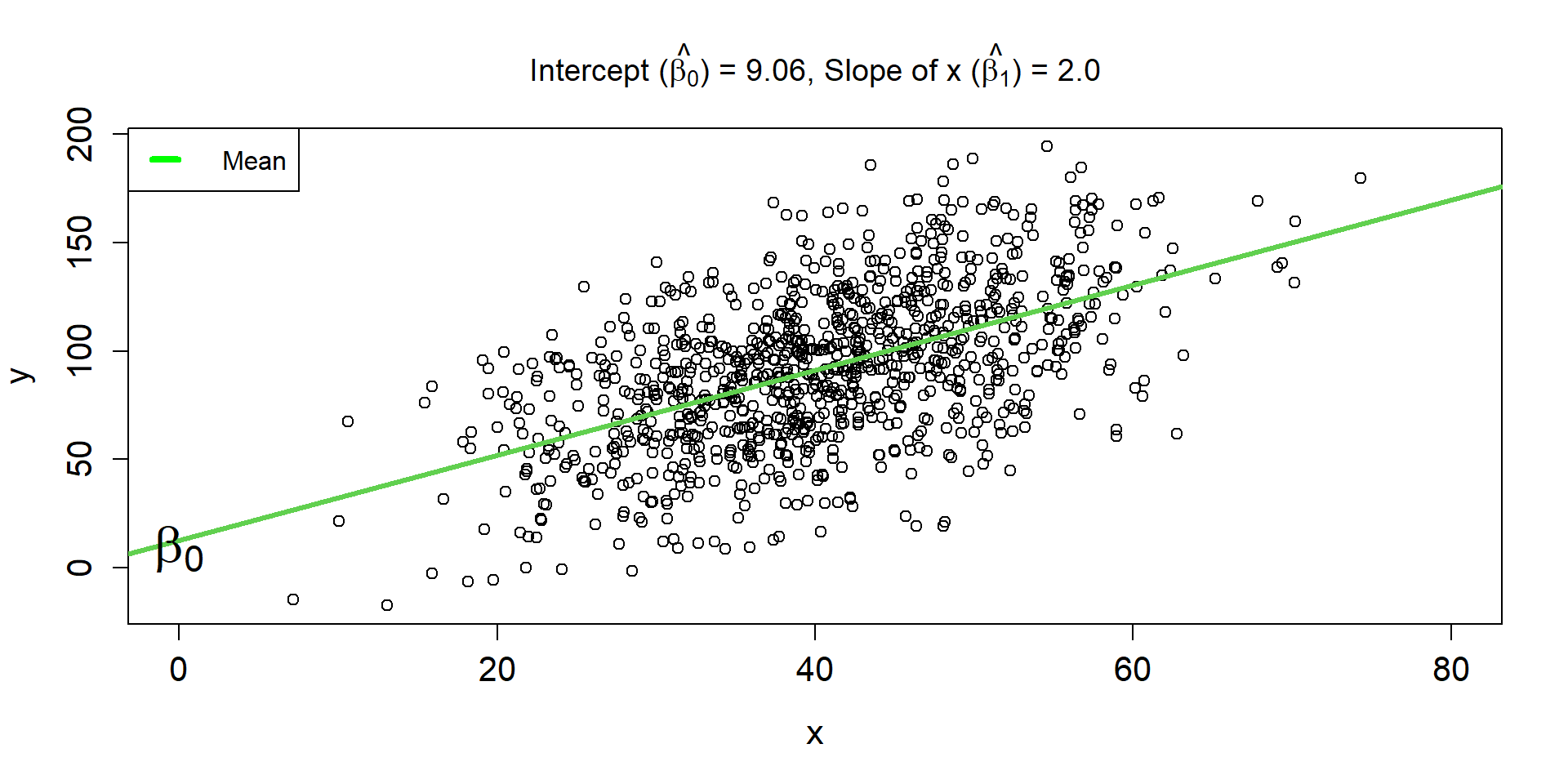
Constancy in the scatter of observations above and below the line, going left to right.
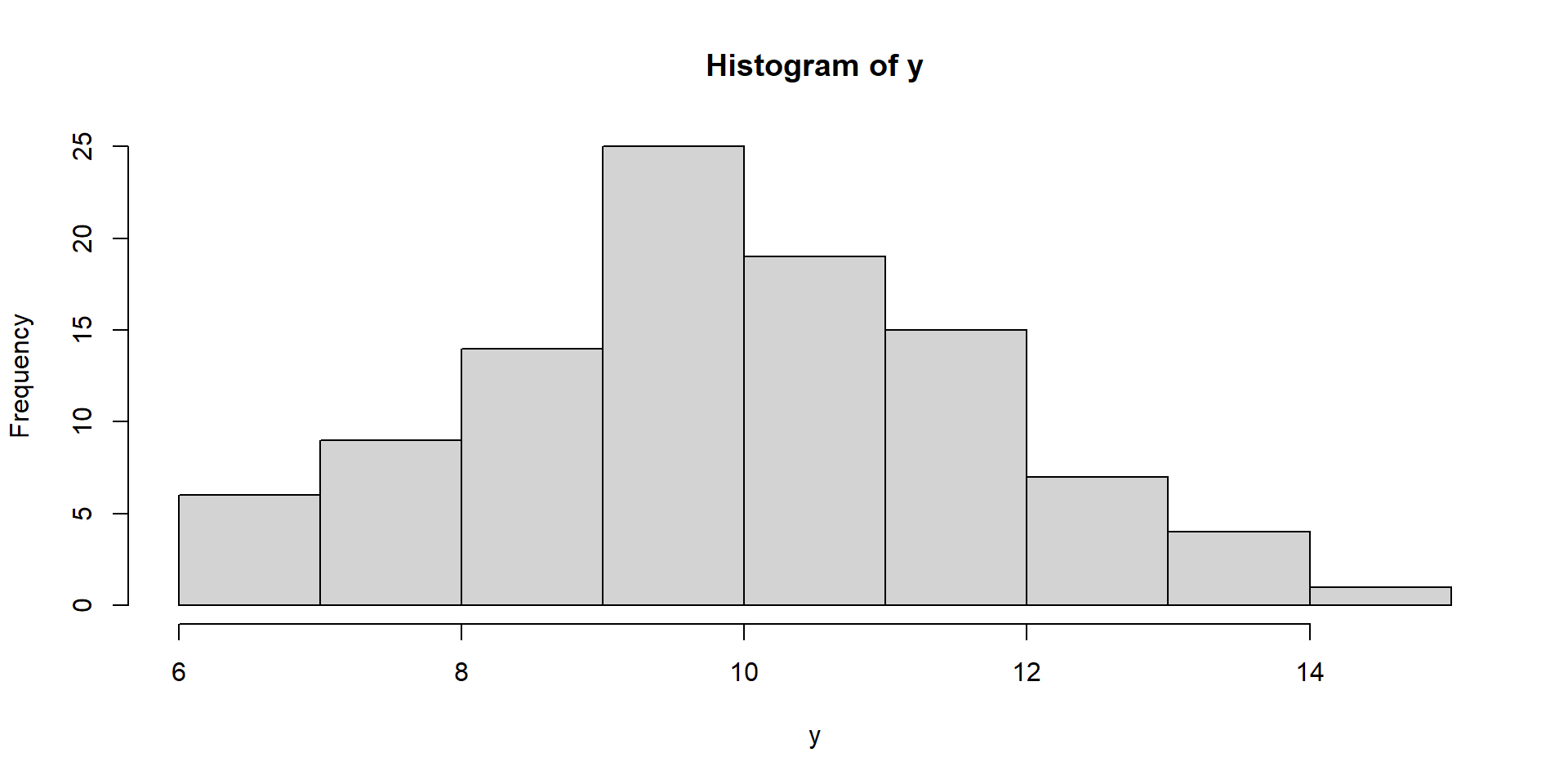
#Setup parameters n =100# sample size beta0 =10# true mean sigma =2# true std.dev# Simulate a data set of observationsset.seed(43243) y =rnorm(n, mean = beta0, sd = sigma)
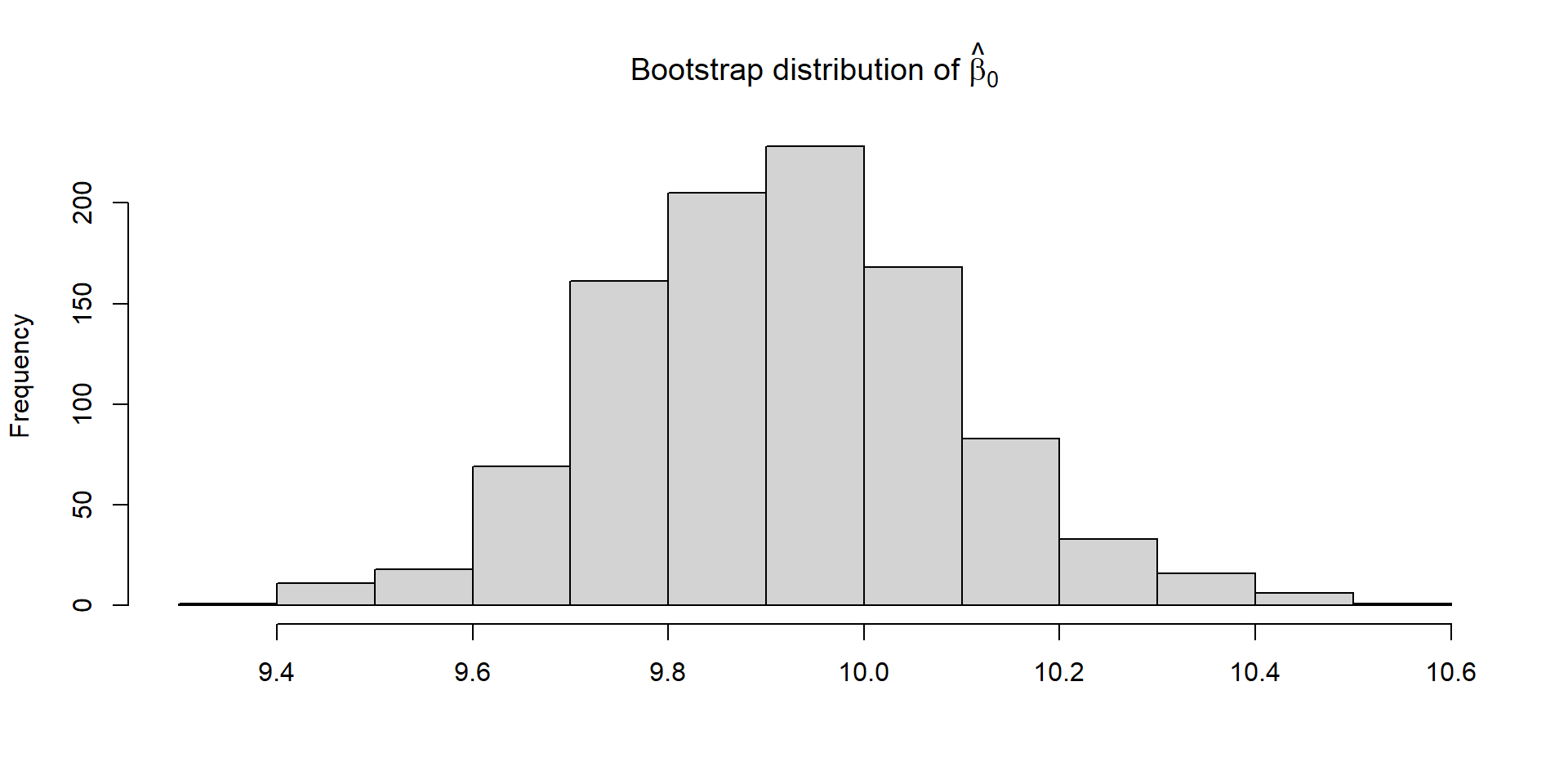
Visualize Intercept-Only Model
hist(y)
Fit Intercept-Only Model
# Fit model/hypothesis using maximum likelihood model1.0=lm(y~1) model1.1=glm(y~1) model1.2=glm(y~1, family=gaussian(link = identity))# Compare Results data.frame(intercept=c(model1.0$coefficients,model1.1$coefficients, model1.2$coefficients),SE =c(summary(model1.0)$coefficients[, 2], summary(model1.1)$coefficients[, 2],summary(model1.2)$coefficients[, 2]) )
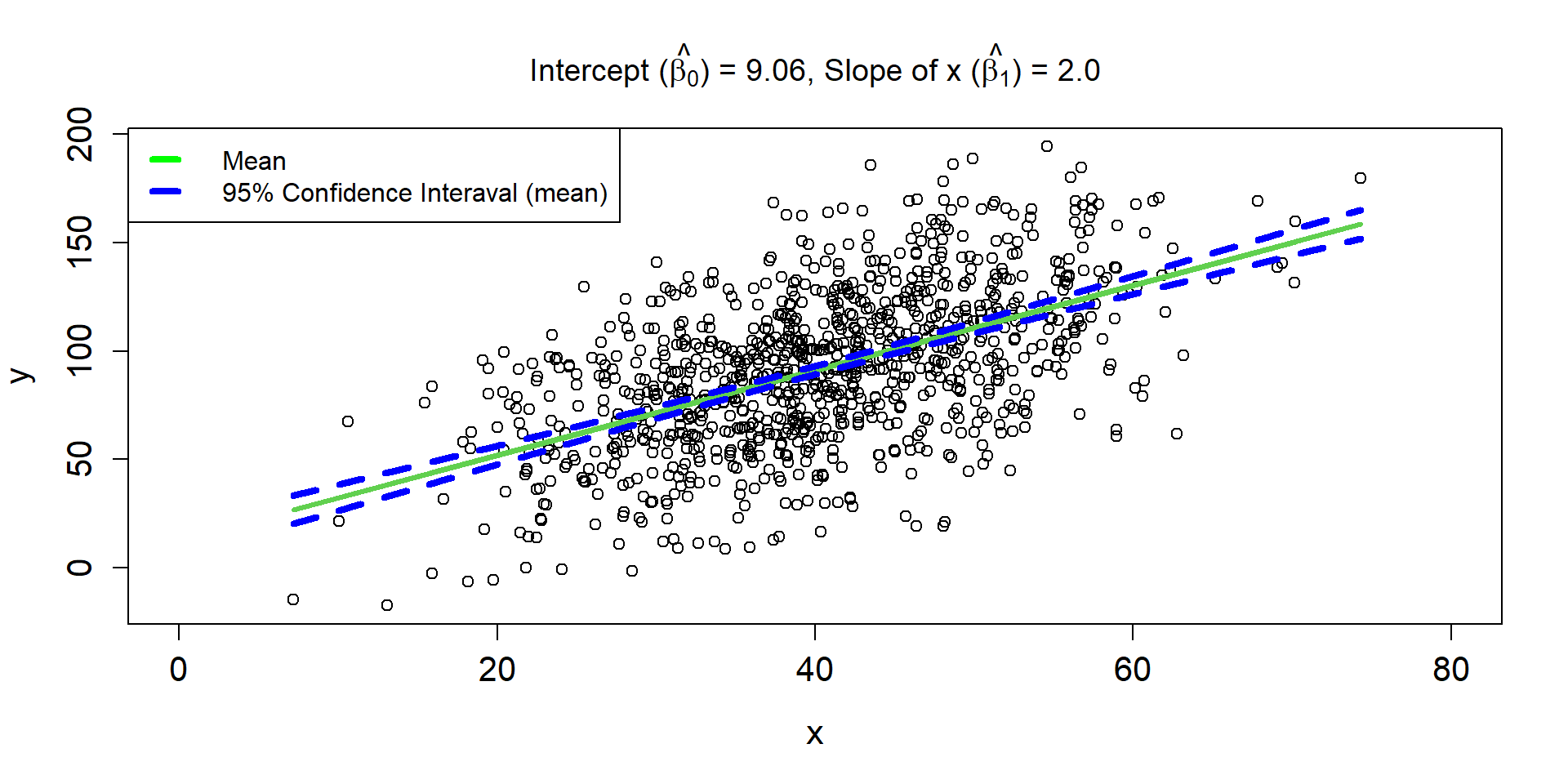
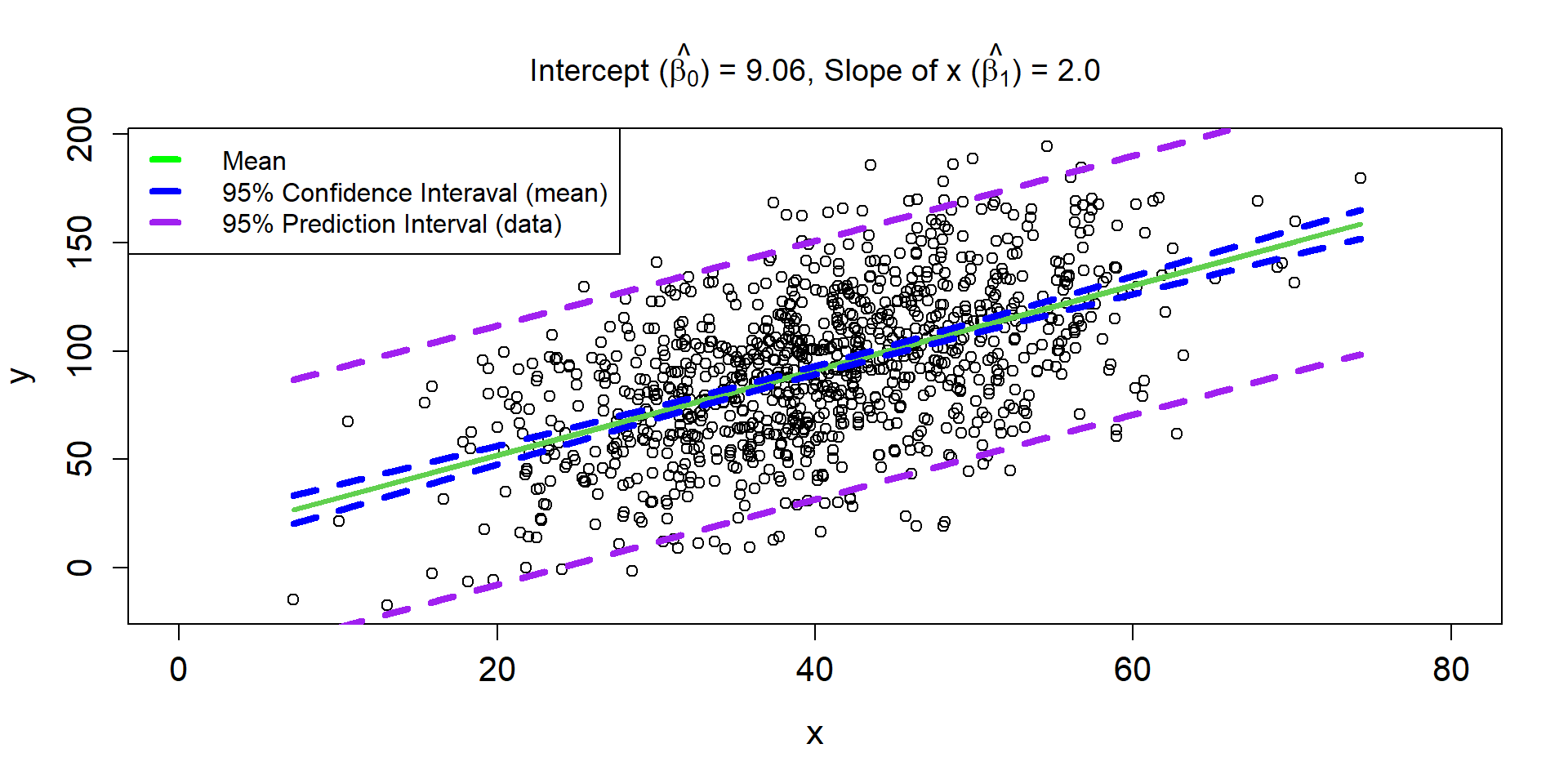
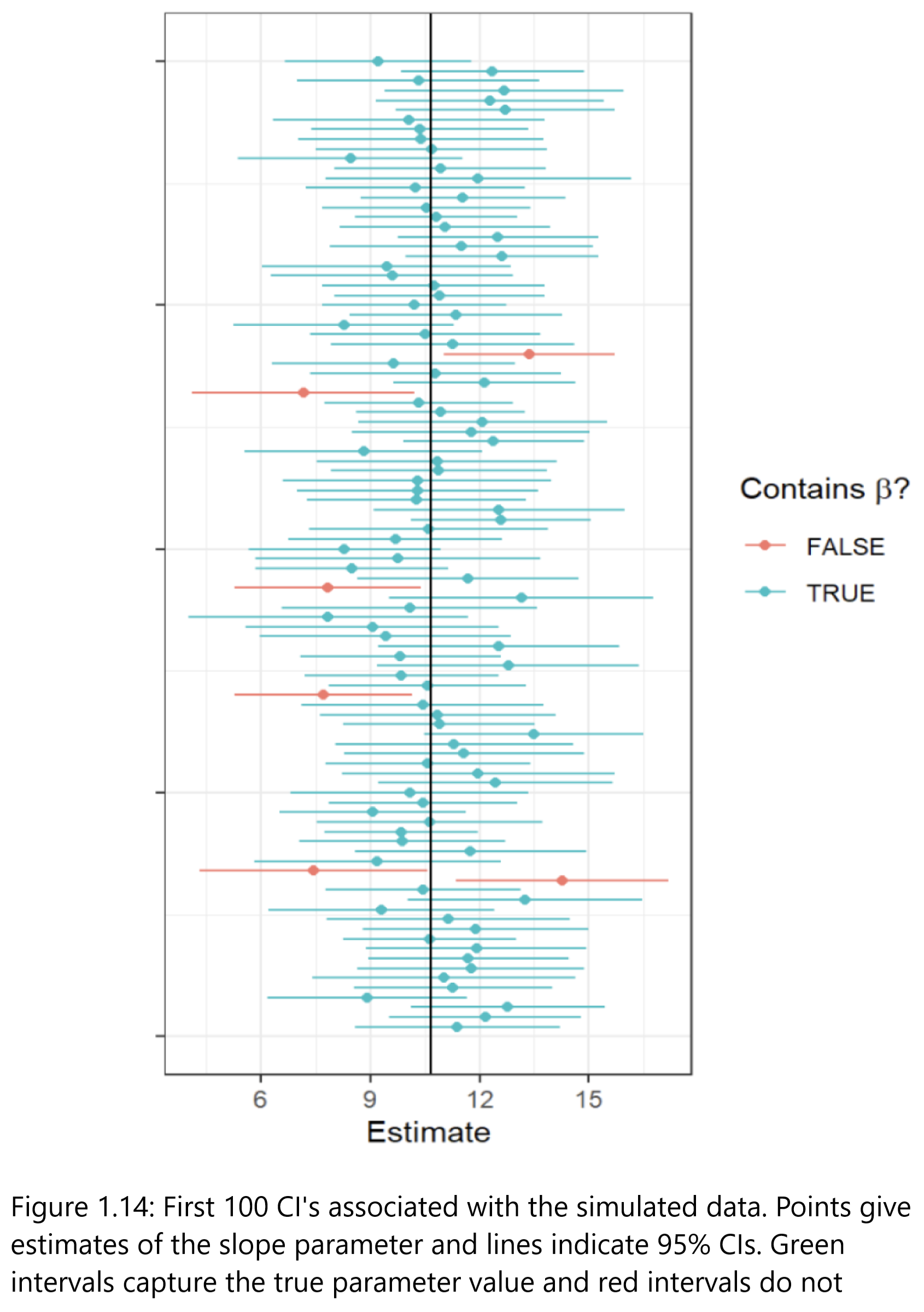
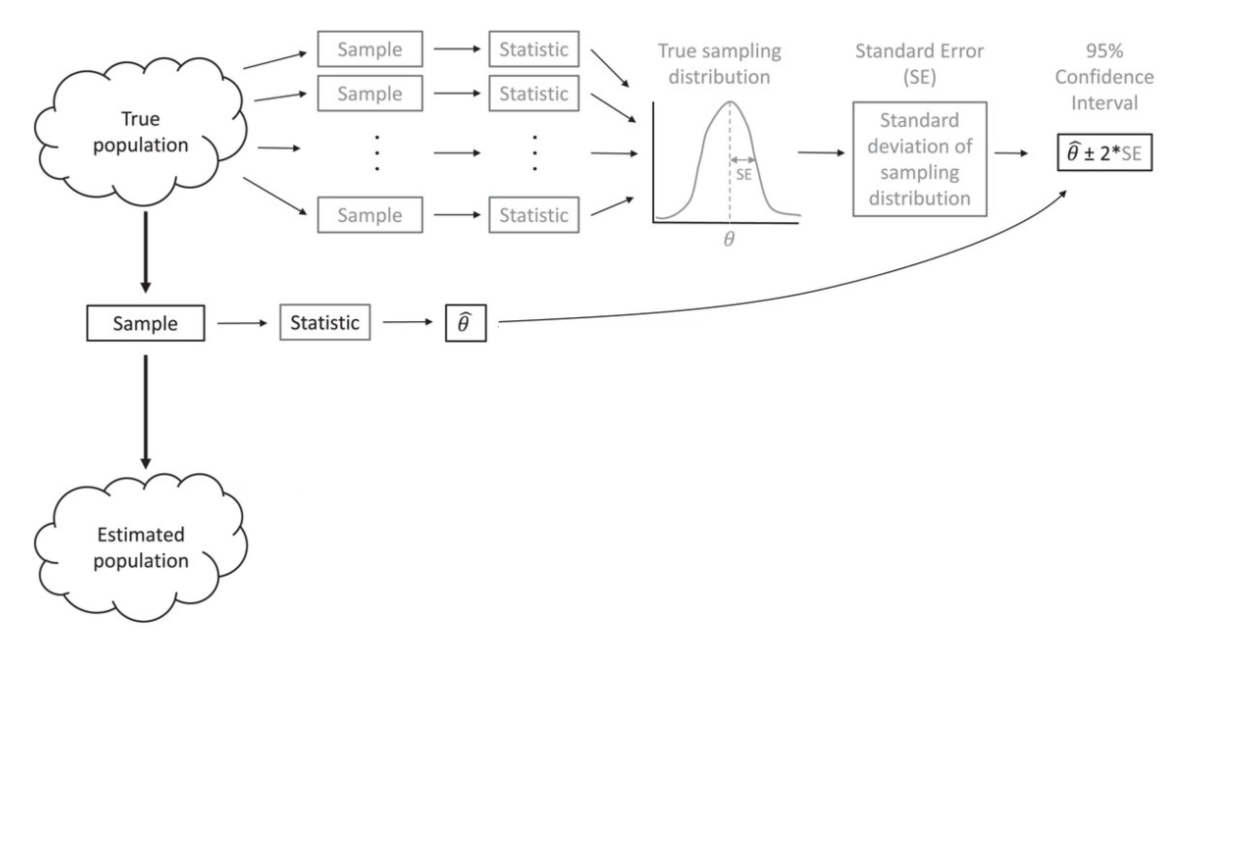
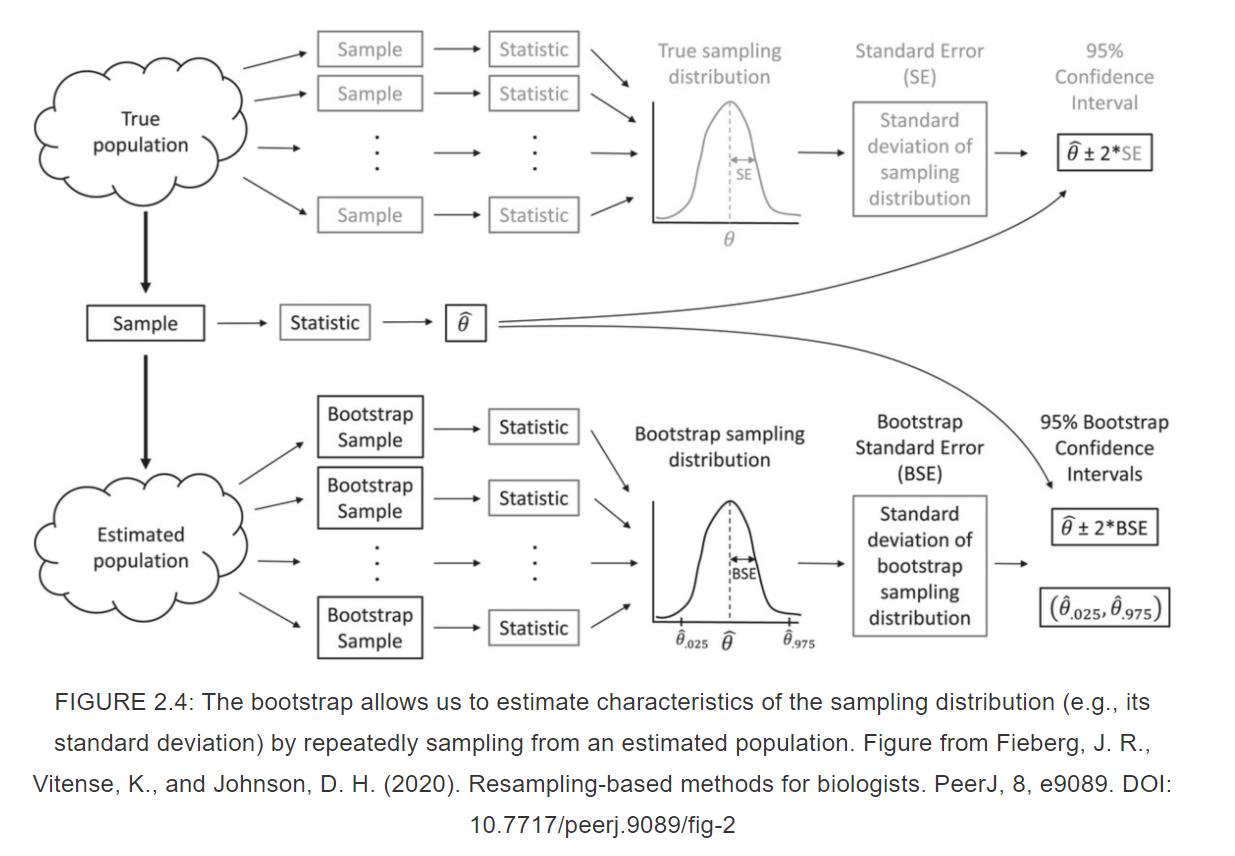
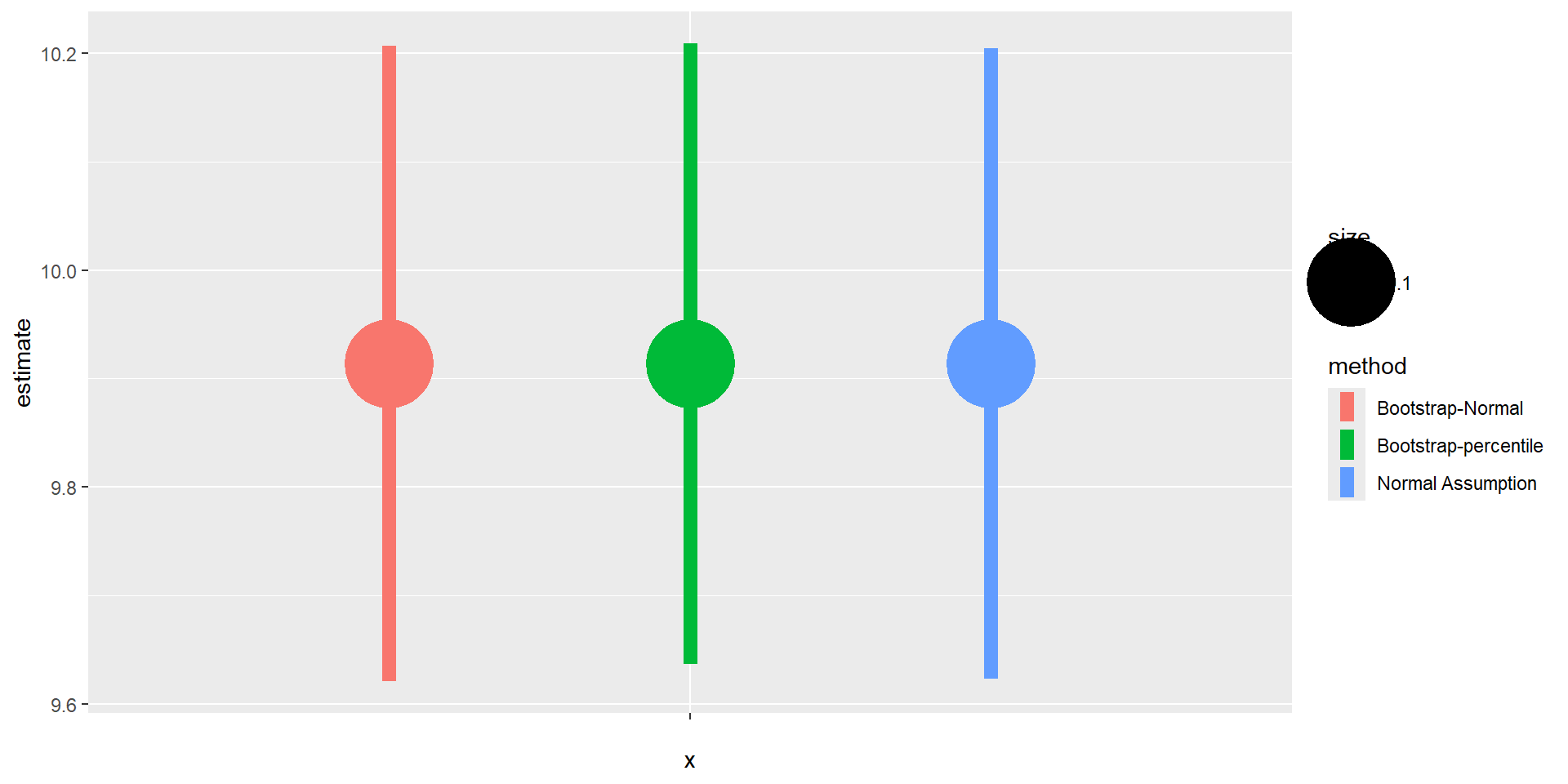
“A confidence interval for a parameter is an interval computed using sample data …
“… by a method that will contain the parameter for a specified proportion of all samples.
The success rate (proportion of all samples whose intervals contain the parameter) is known as the confidence level.” R. H. Lock et al. (2020)
What is a CI?
Key
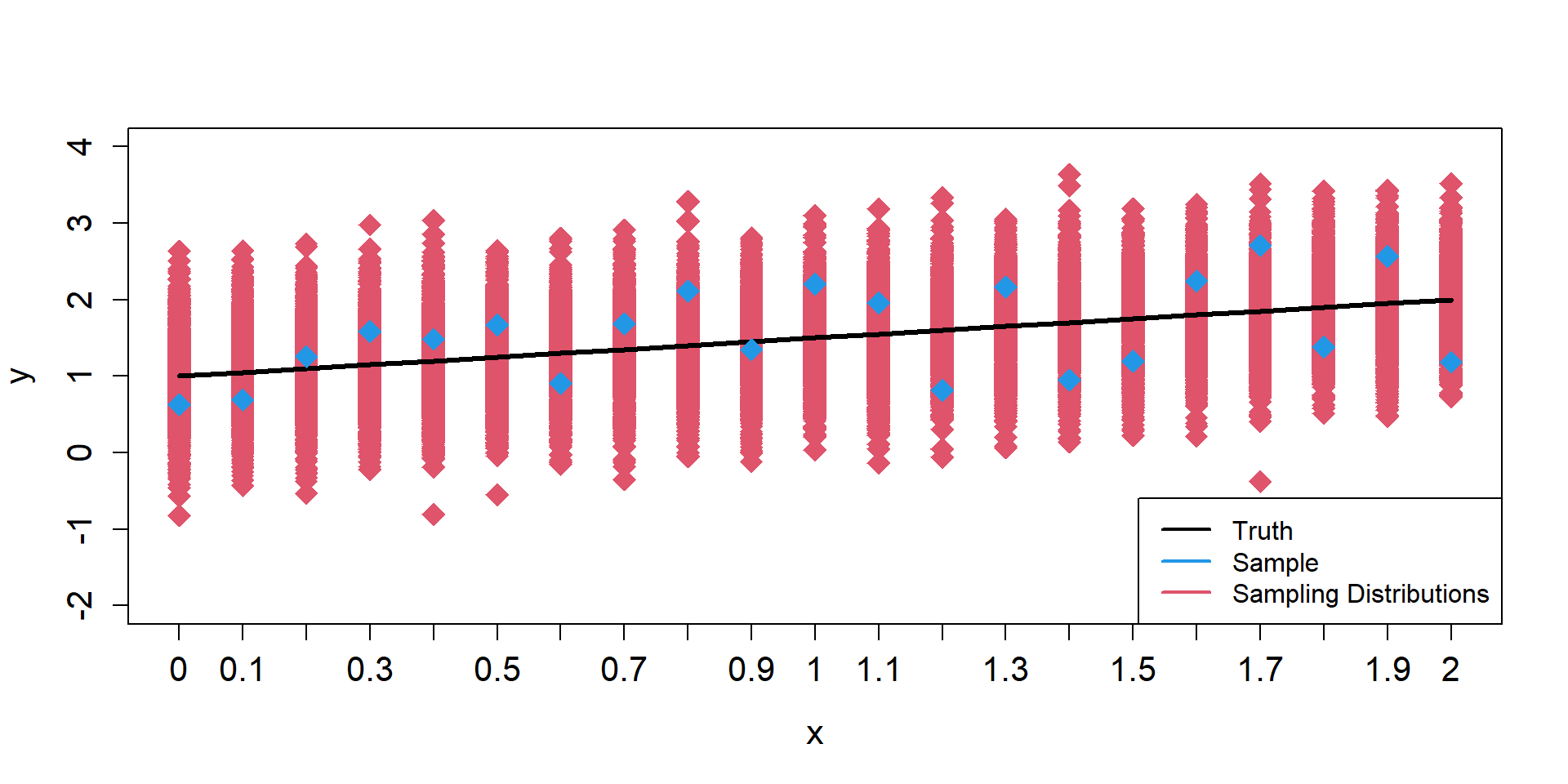
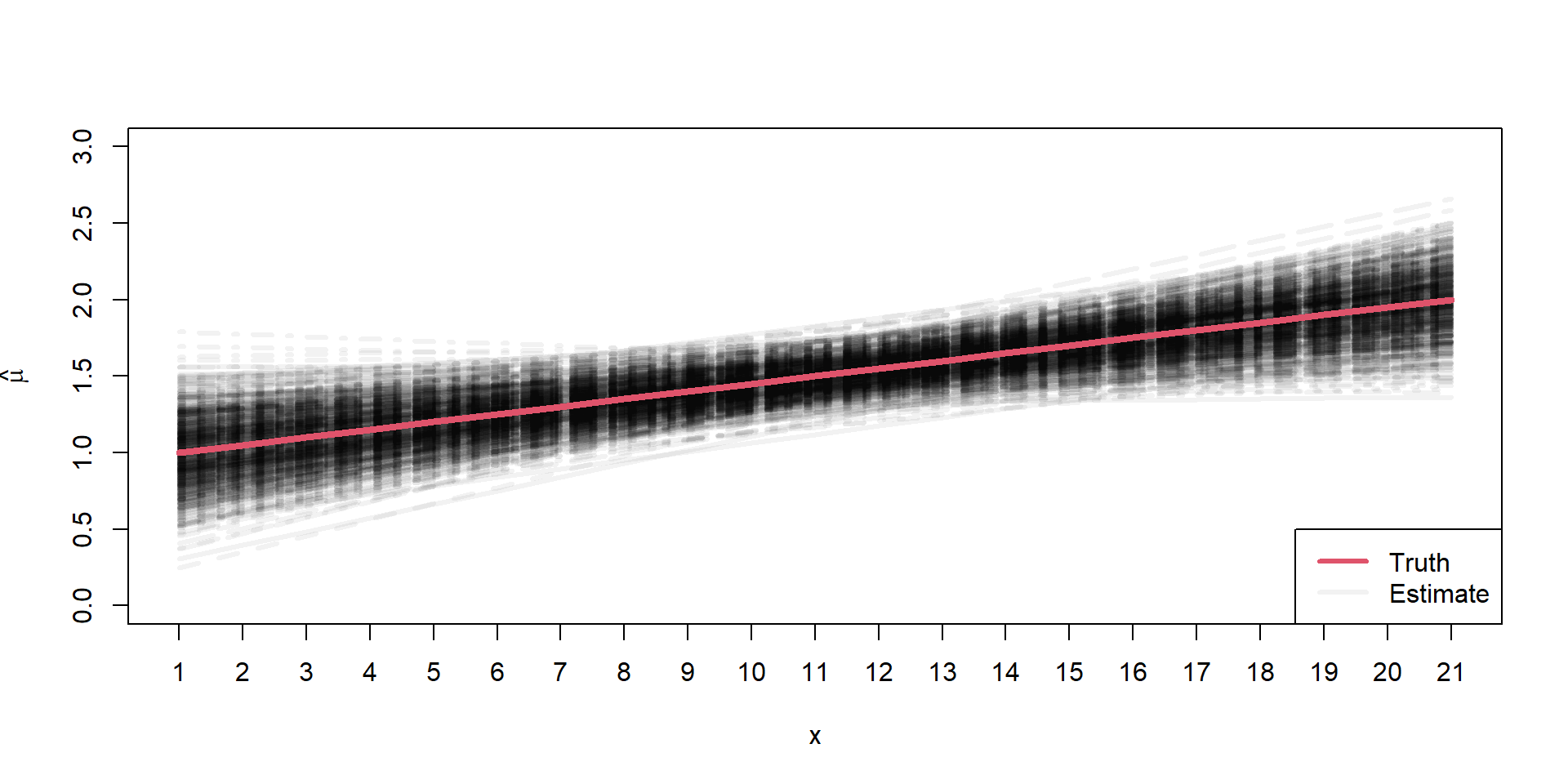
the parameter we are trying to estimate is a fixed unknown (i.e., it is not varying across samples)
the endpoints of our confidence interval are random and will change every time we collect a new data set (the endpoints themselves actually have a sampling distribution!)
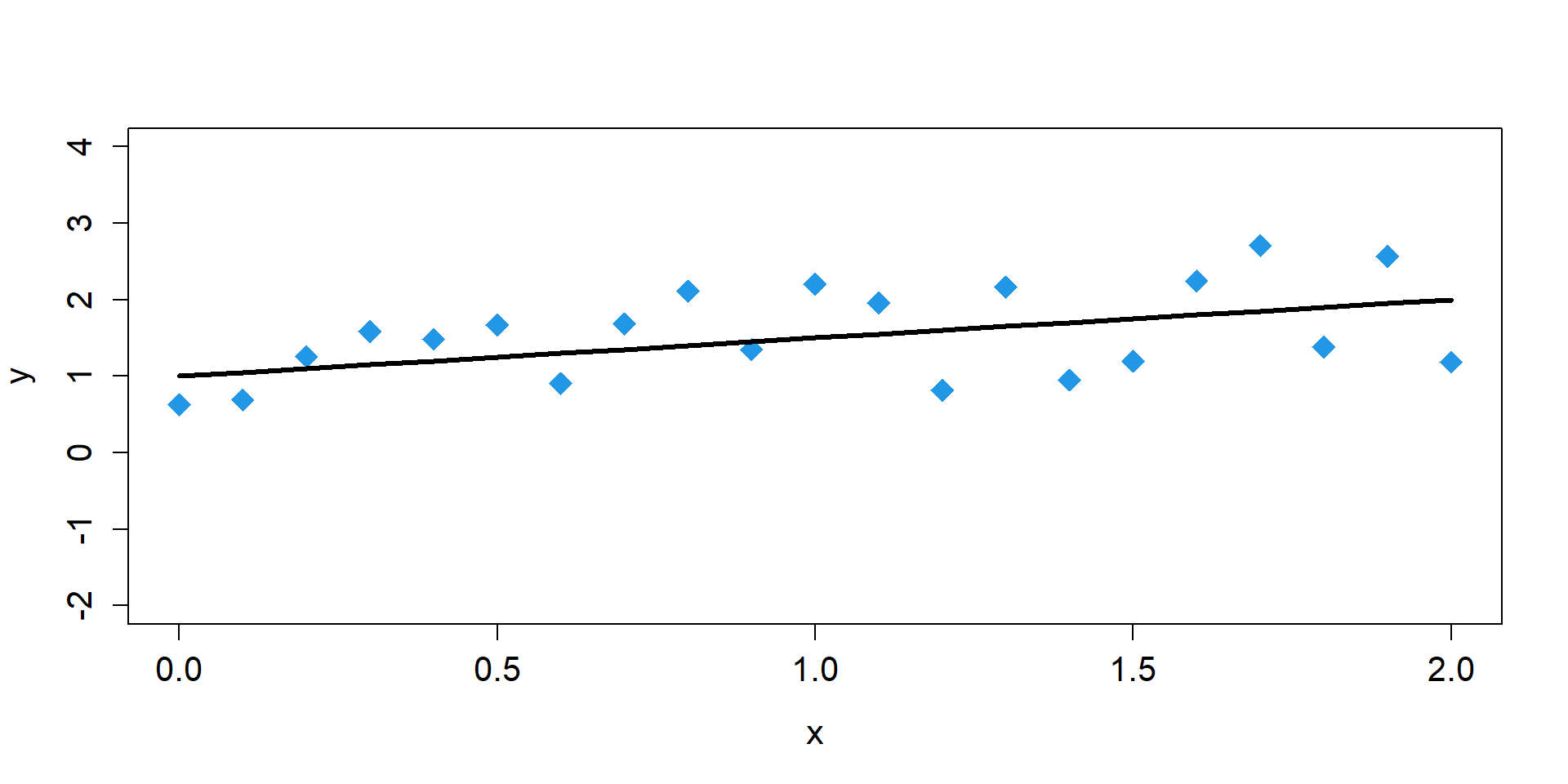
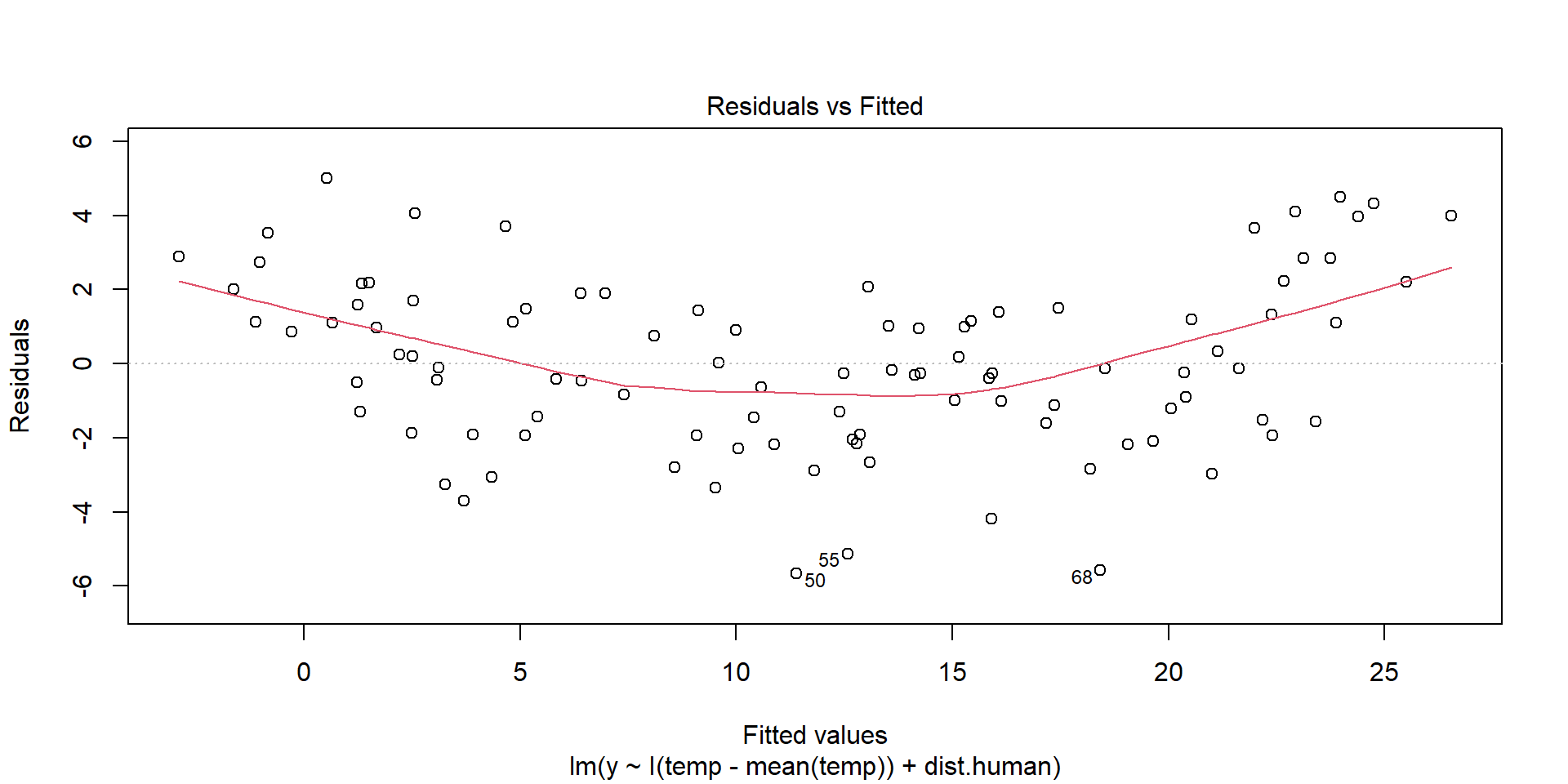
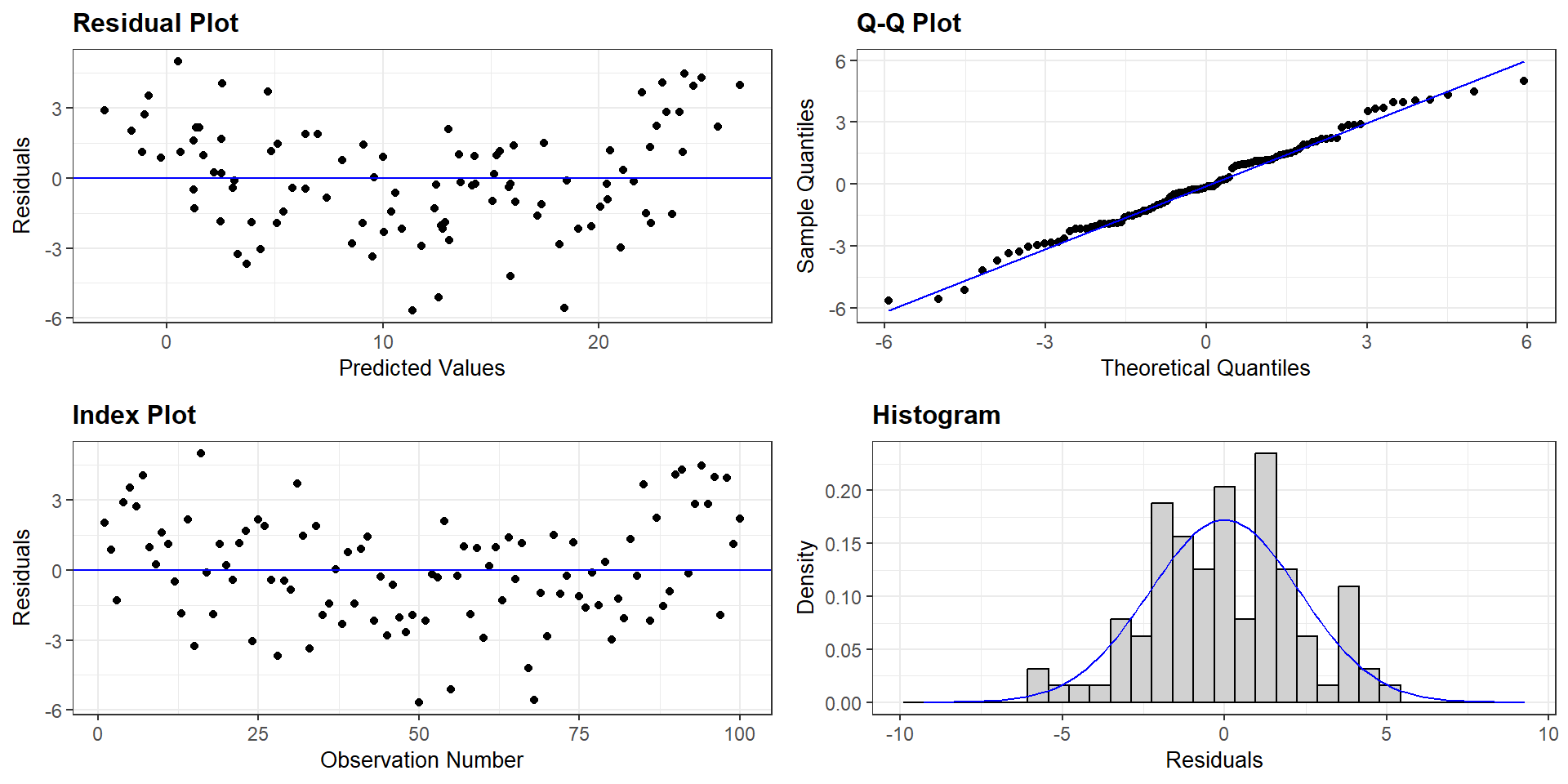
Ideally, there will be no pattern and the red line should be roughly horizontal near zero.
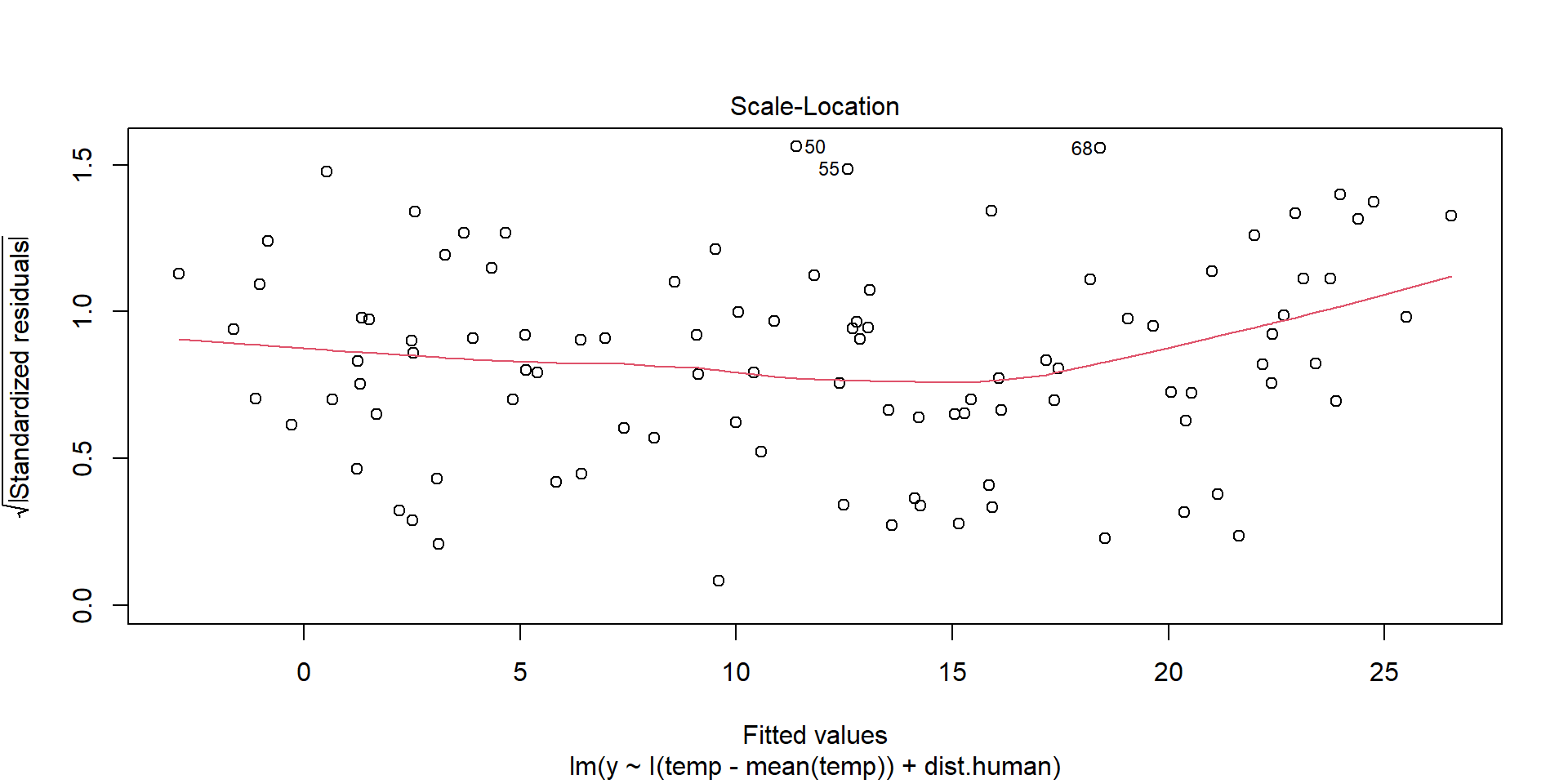
Homogeneity of Variance
plot(model,3)
Residuals should be spread equally along the ranges of predictors. We want a horizontal red line; otherwise, suggests a non-constant variances in the residuals (i.e., heteroscedasticity).
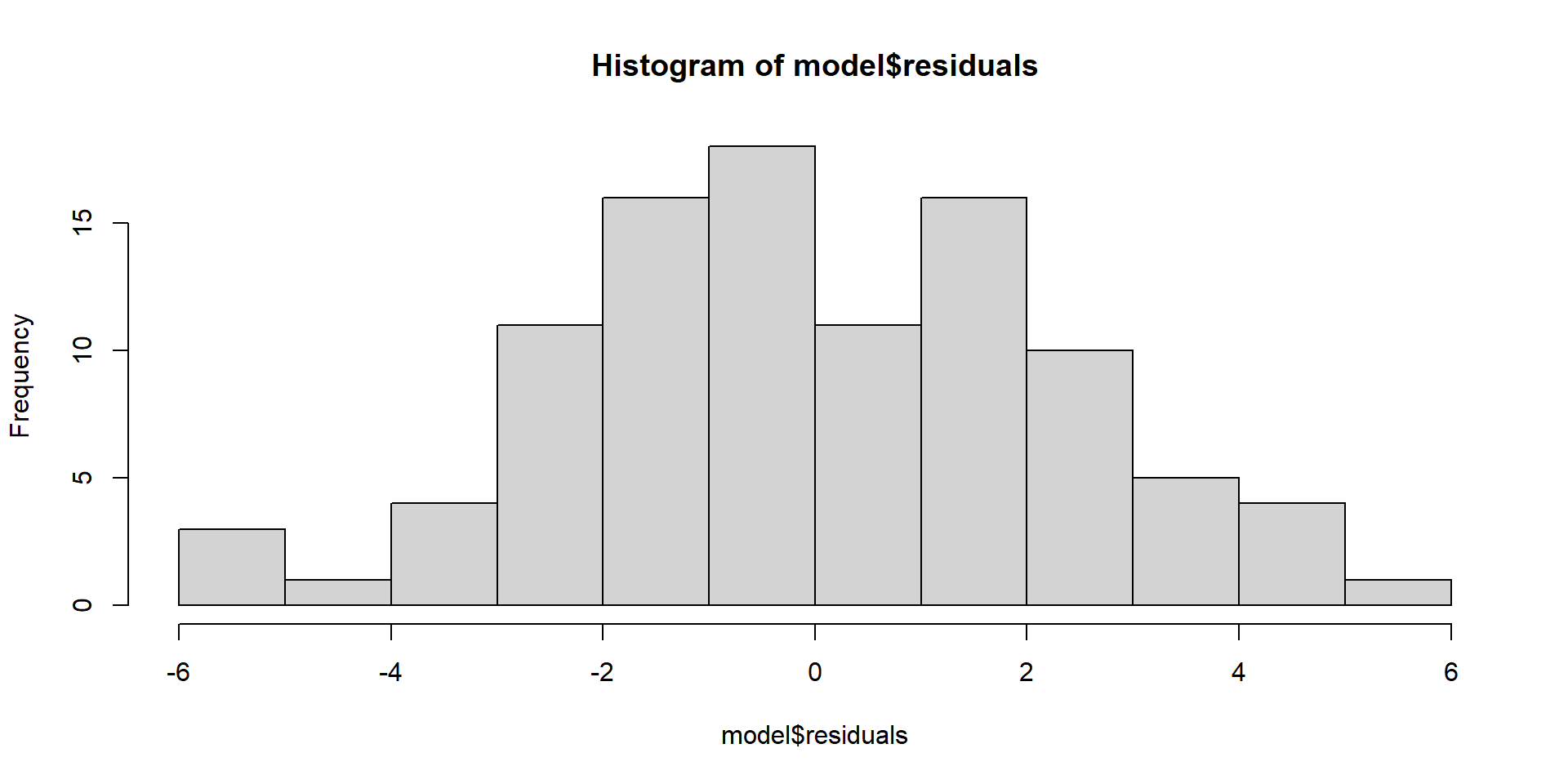
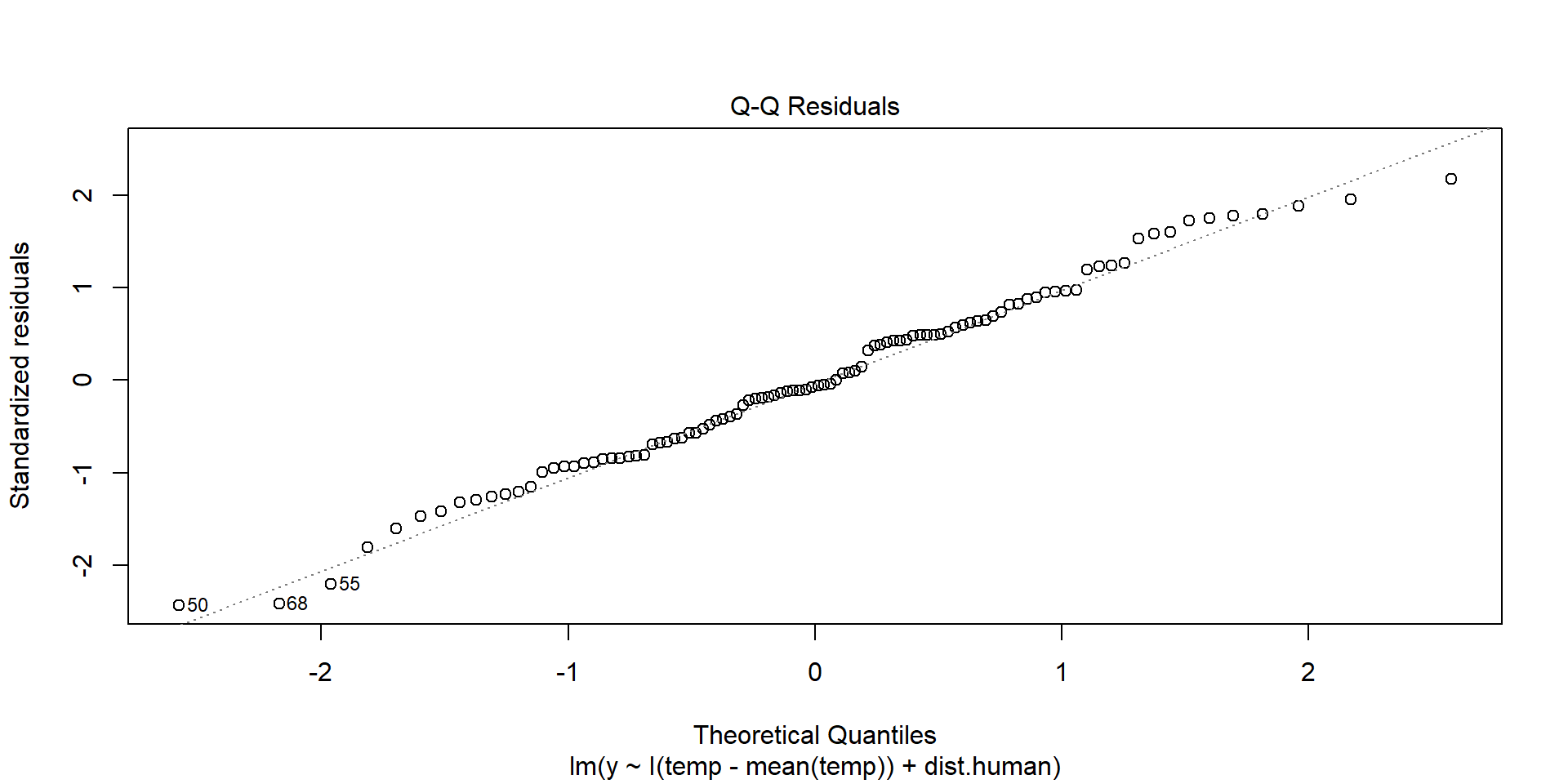
Normality of Residuals
plot(model,2)
Shows theoretical quantiles versus empirical quantiles of the residuals. We want to see cicles on the dotted line.
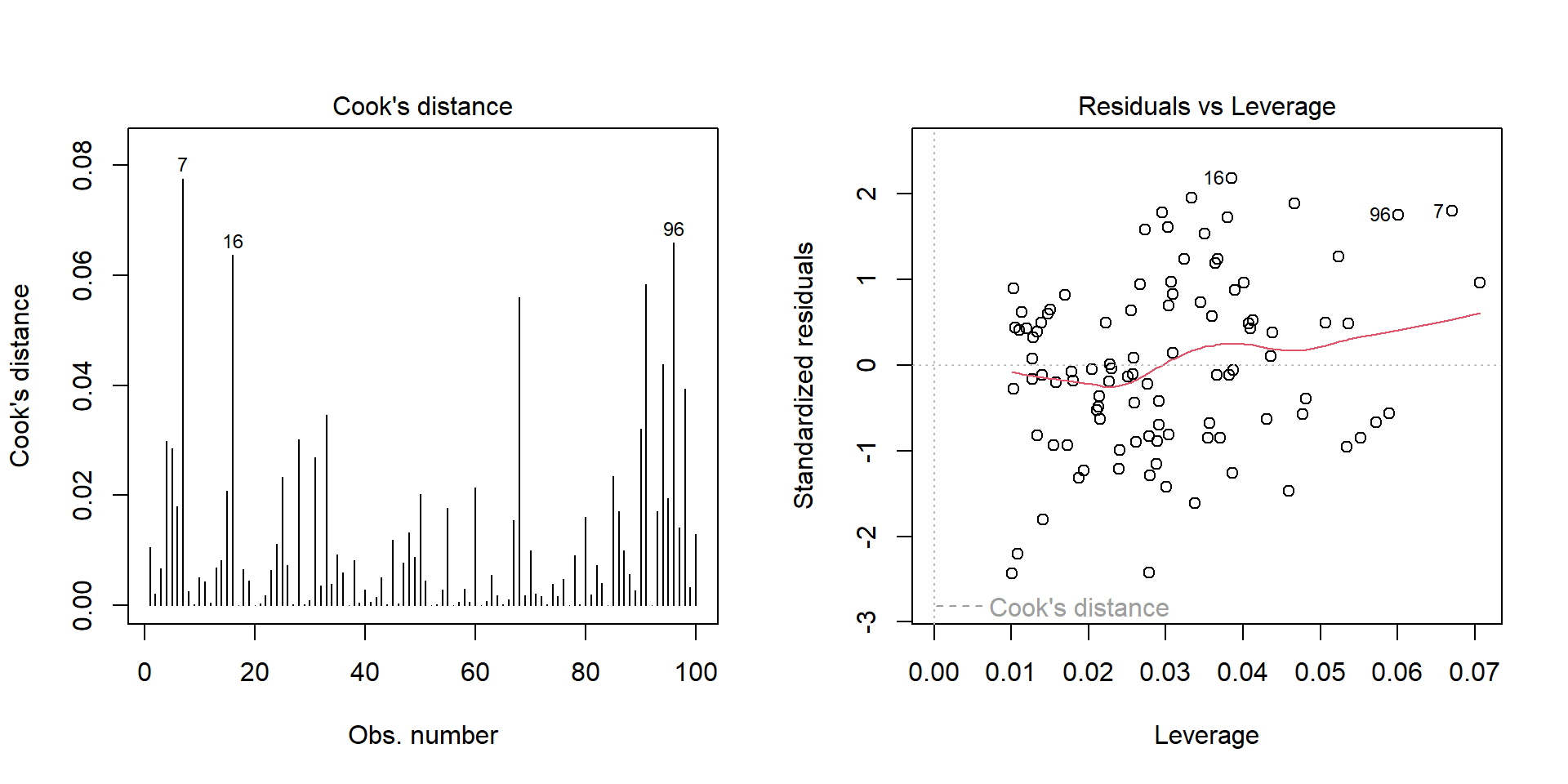
Outliers
par(mfrow=c(1,2))plot(model,4)plot(model,5)
Outlier: extreme value that can affect the \(\beta\) estimate. Leverage plot: points in the upper right and lower right corner.