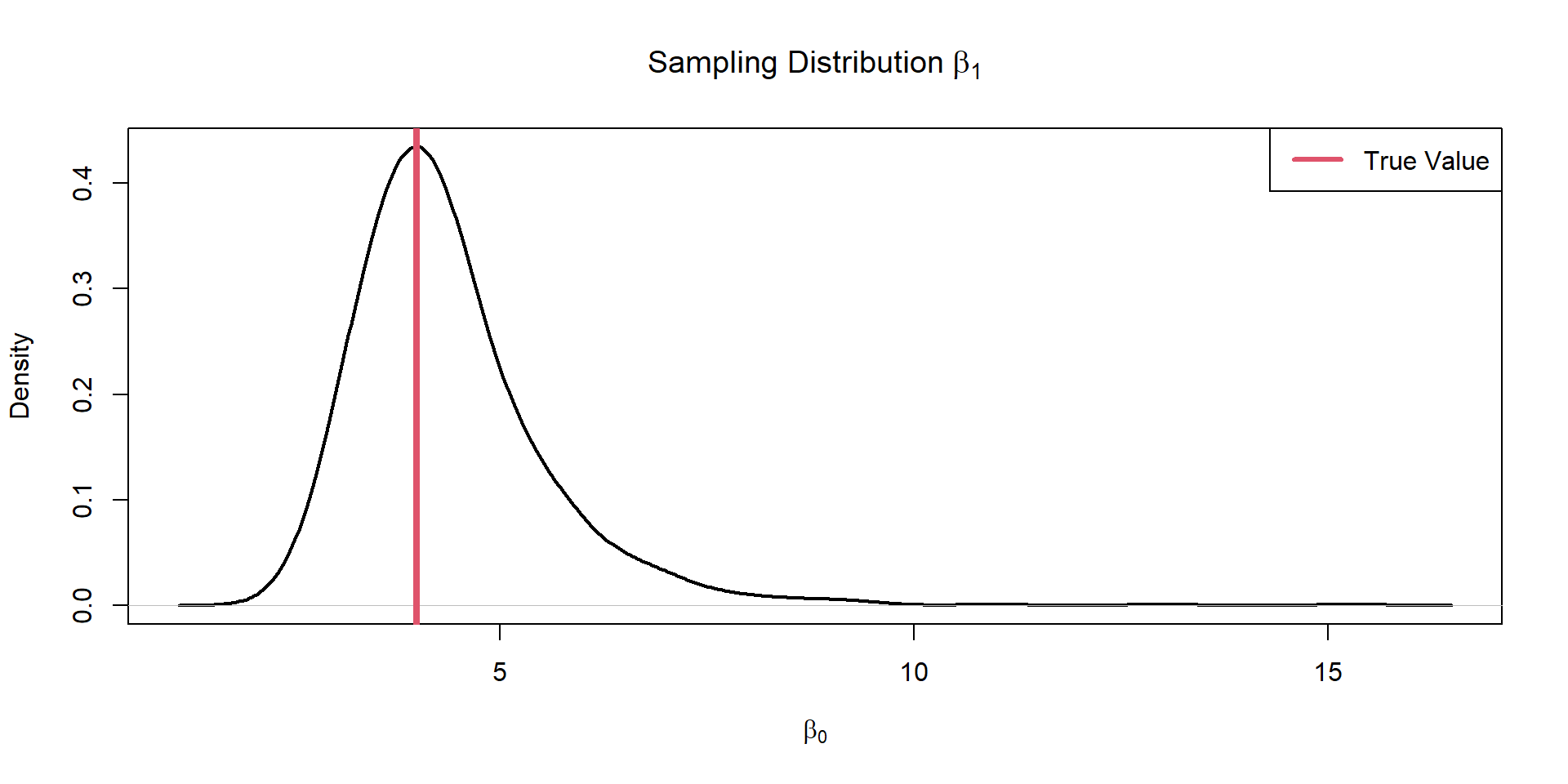
[,1]
[1,] 14Generalized Linear Models
GLM
Generalized linear model framework using matrix notation
\[ \begin{align*} \textbf{y}\sim& [\textbf{y}|\boldsymbol{\mu},\sigma] \\ \text{g}(\boldsymbol{\mu}) =& \textbf{X}\boldsymbol{\beta} \end{align*} \]

Link functions
\(\text{g}(\boldsymbol{\mu}) = \textbf{X}\boldsymbol{\beta}\)
\(\boldsymbol{\mu} = \text{g}^{-1}(\textbf{X}\boldsymbol{\beta})\)
Link functions map parameters from one support to another.
Why is that important for us?
To put a linear model on parameters of interest and ensure the parameter support is maintained.
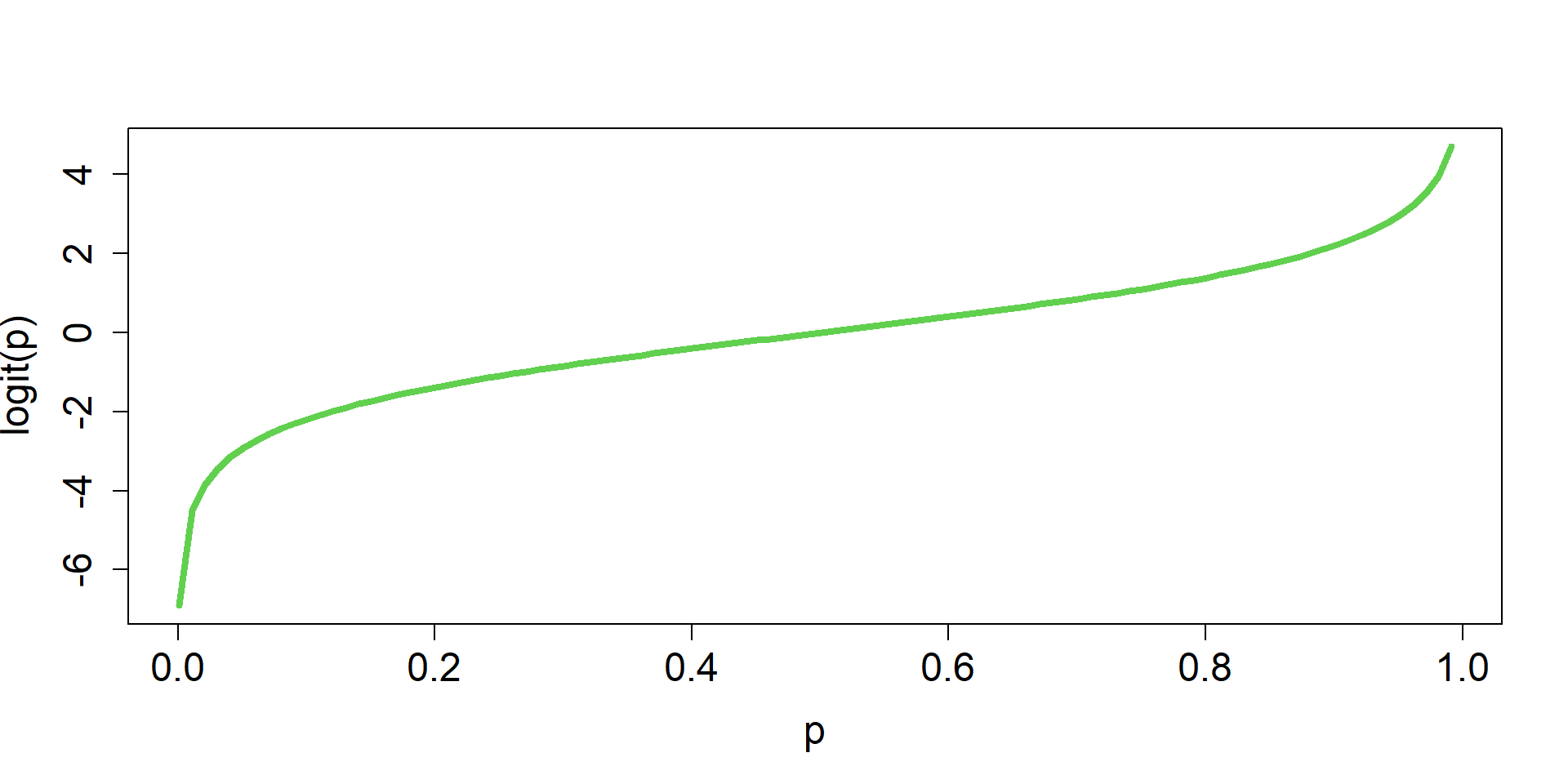
Computers do not like boundaries (e.g., 0 or 1). It’s easier to guess values to evaluate in a maximum liklihood optimization when there are no bounds. (\(-\infty\), \(\infty\))
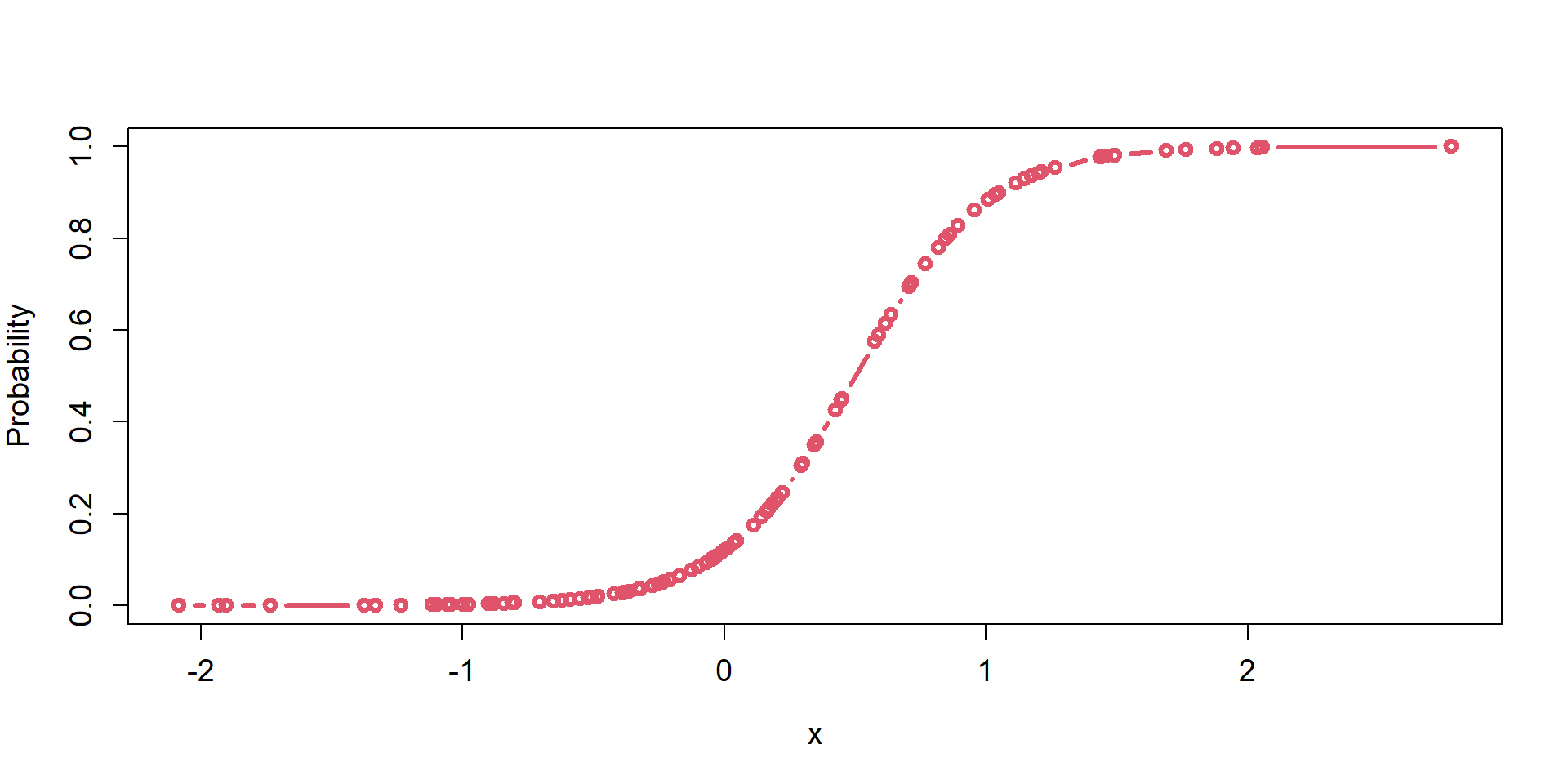
logit/p mapping
Logistic Regression Simulation
# marginal coefficients (on logit-scale)
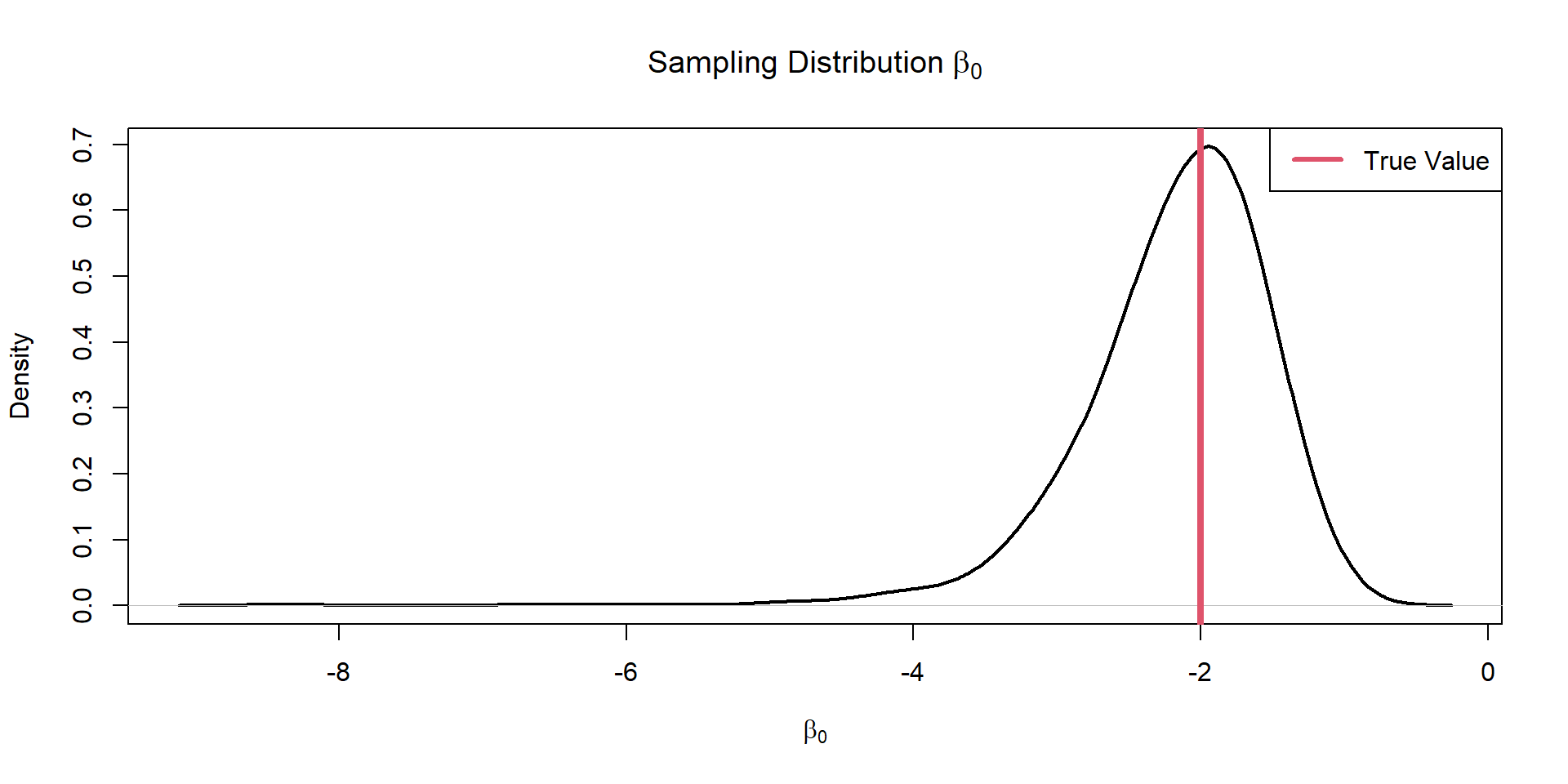
beta=c(-2,4)
#linear terms
lt = X%*%beta
#transformation via link function to probability scale
p=plogis(lt)
head(round(p,digits=2)) [,1]
1 0.98
2 0.02
3 0.90
4 0.01
5 0.95
6 0.00 [1] 1 0 1 0 1 0 0 1 0 1 0 0 0 1 1 0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0
[38] 0 1 1 0 1 0 1 0 1 1 0 1 1 1 1 0 0 1 1 0 1 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0
[75] 0 0 0 0 0 1 1 0 0 1 0 0 0 0 1 1 0 0 1 0 0 0 0 0 1 0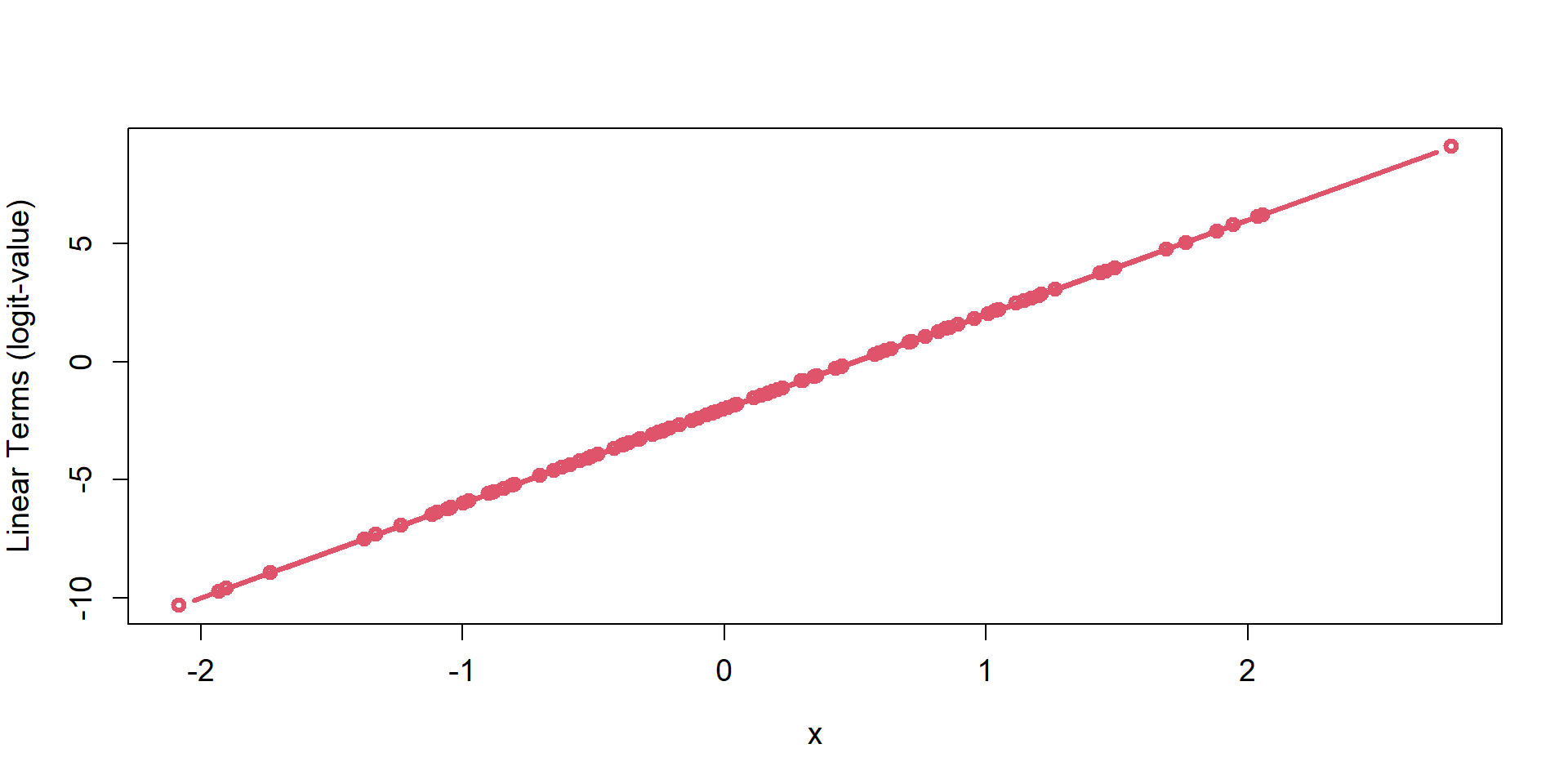
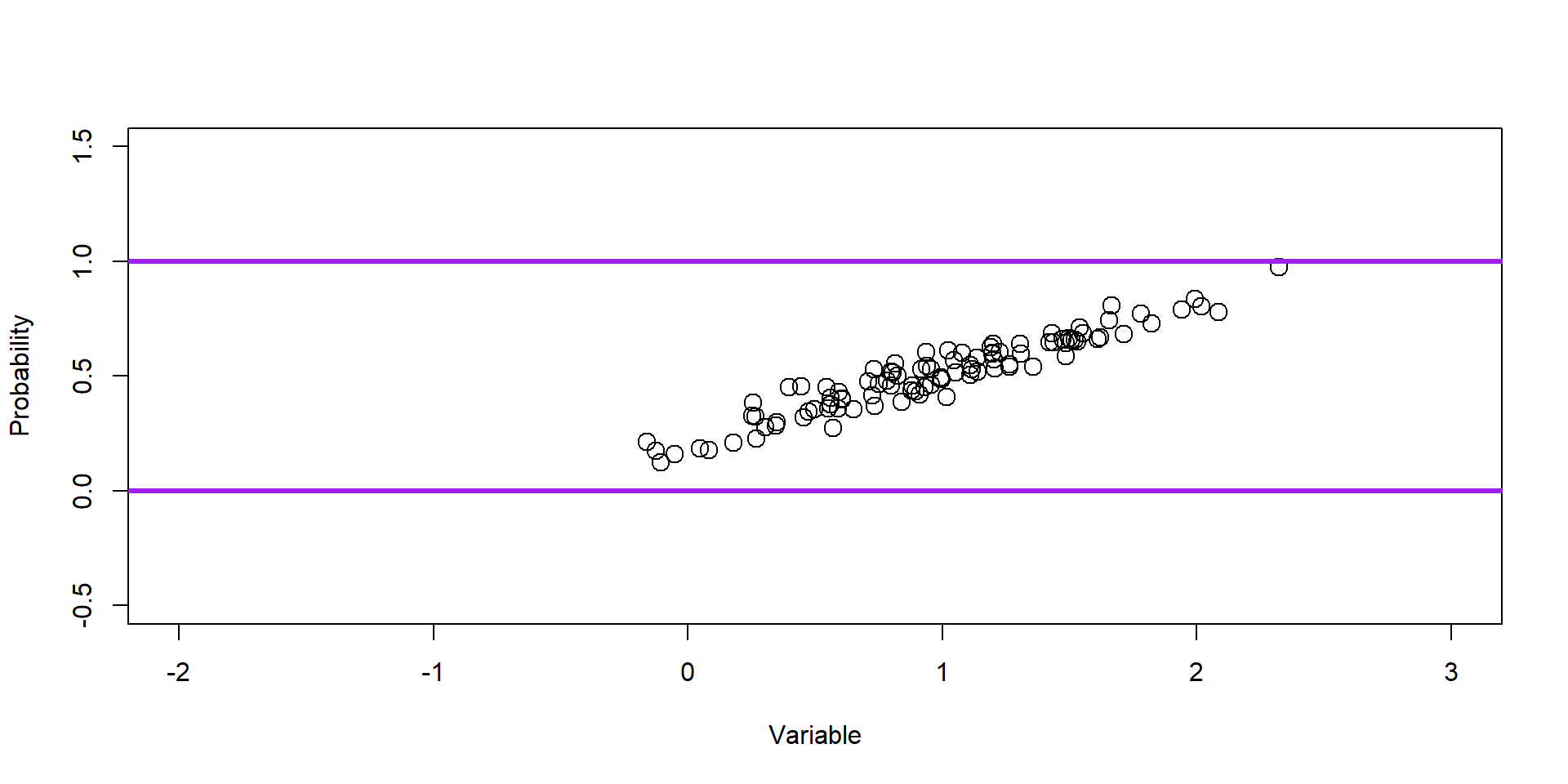
Plot Intercept
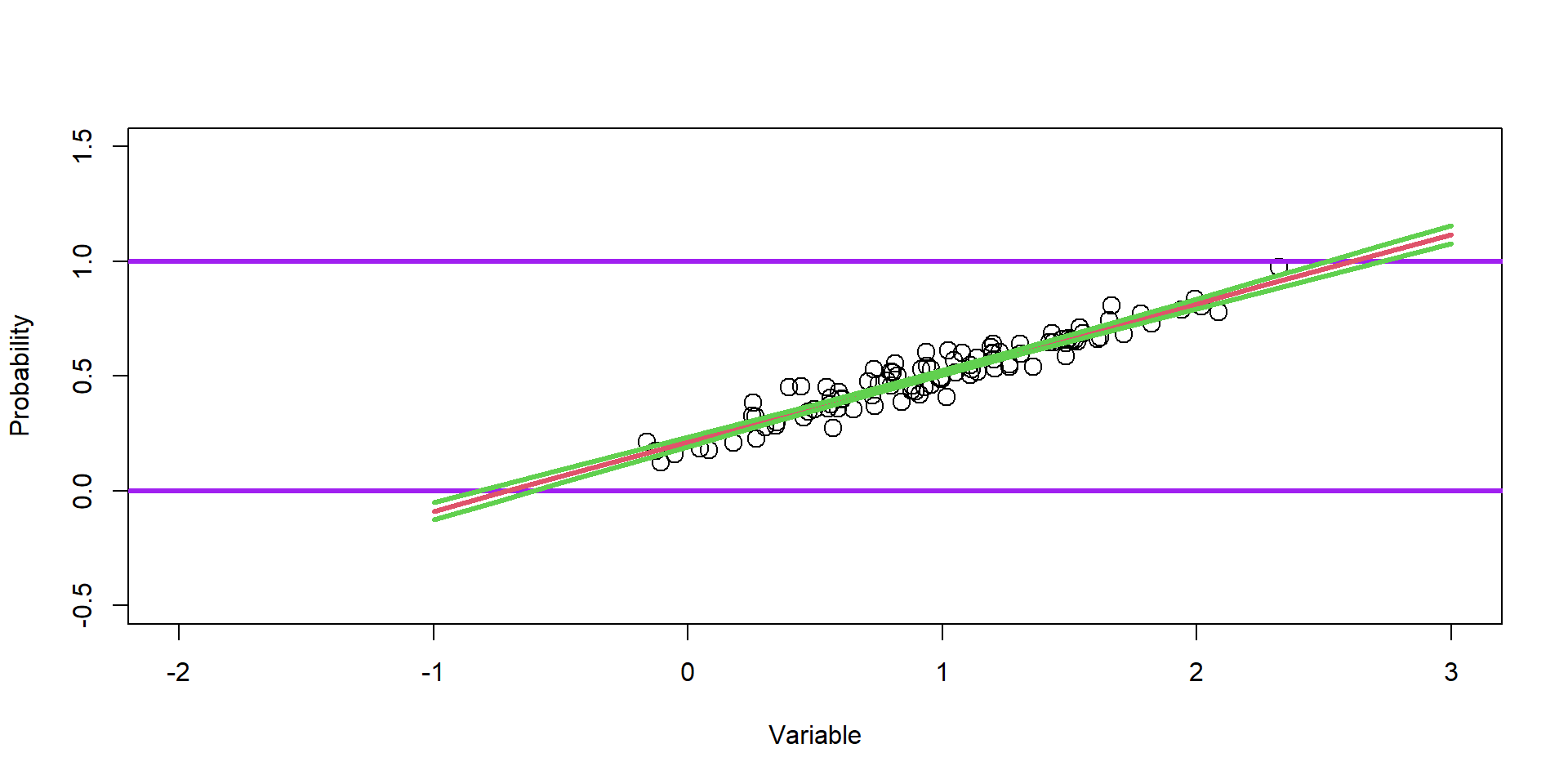
Plot Slope