[1] 102.67671 81.11546 81.75260 87.77246 73.99043 80.70631 76.26219
[8] 83.99927 64.74208 26.93133
Bayes the way
Likelihood Inference
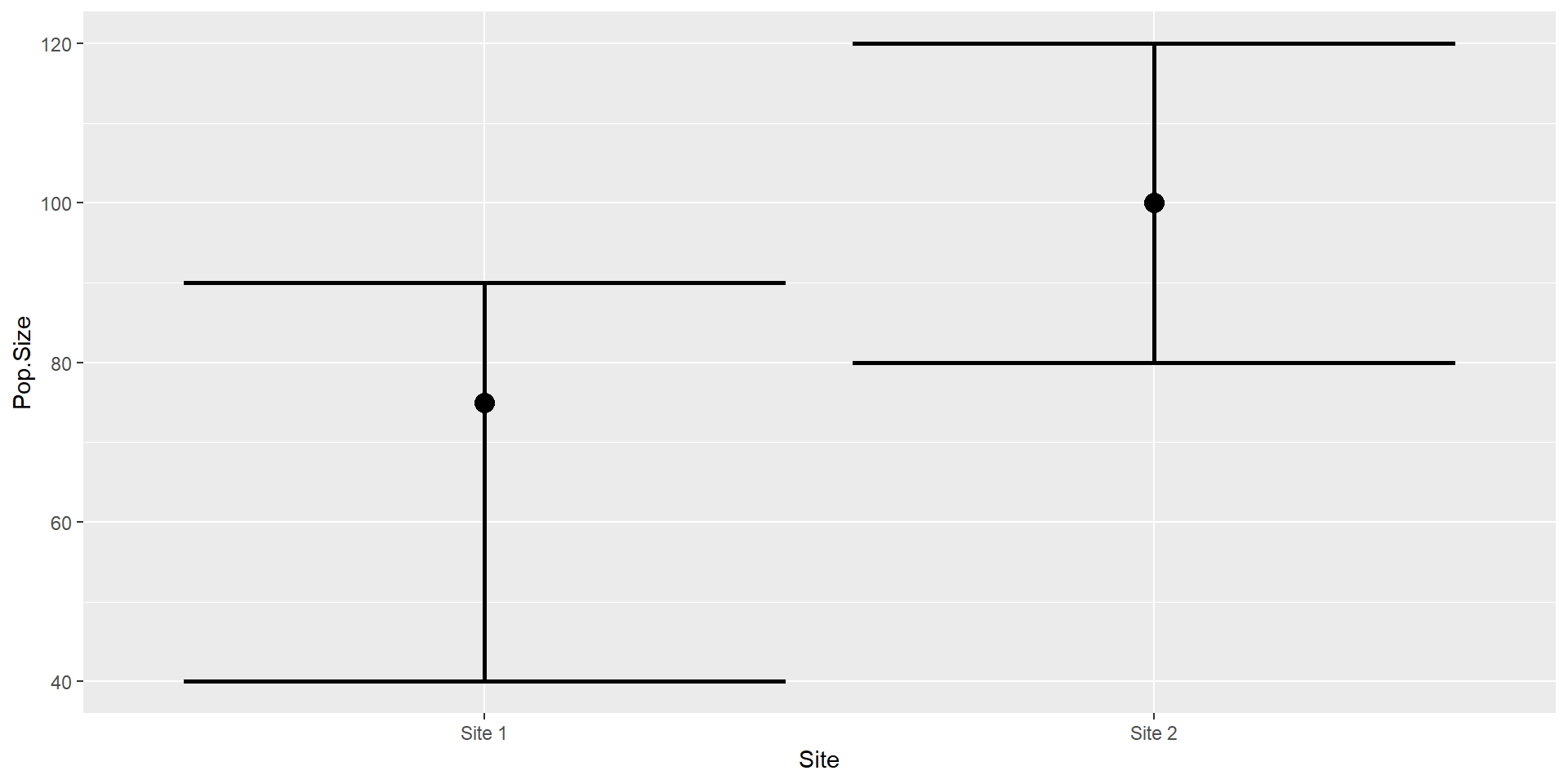
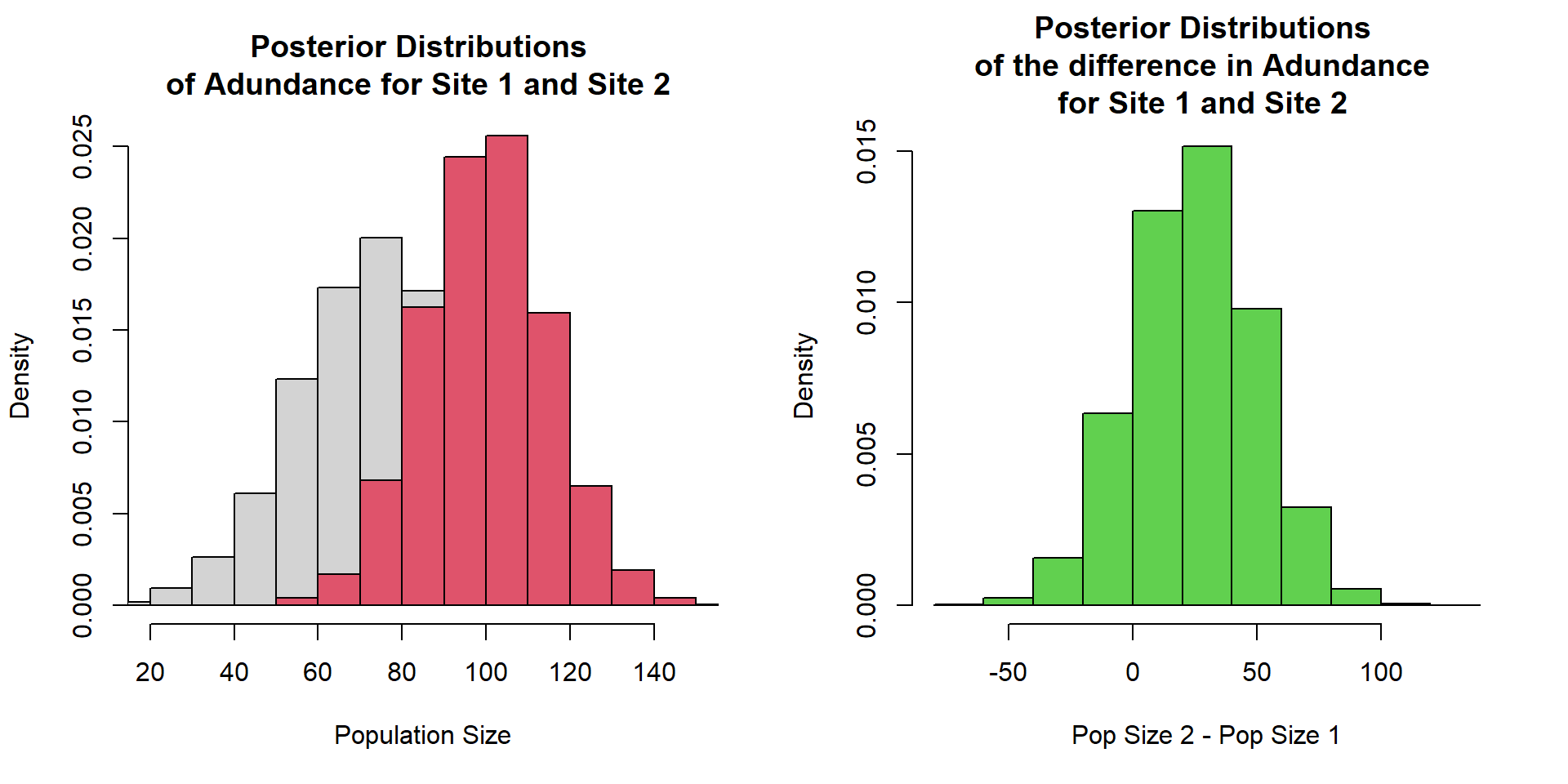
Estimate of the population size of hedgehogs at two sites.
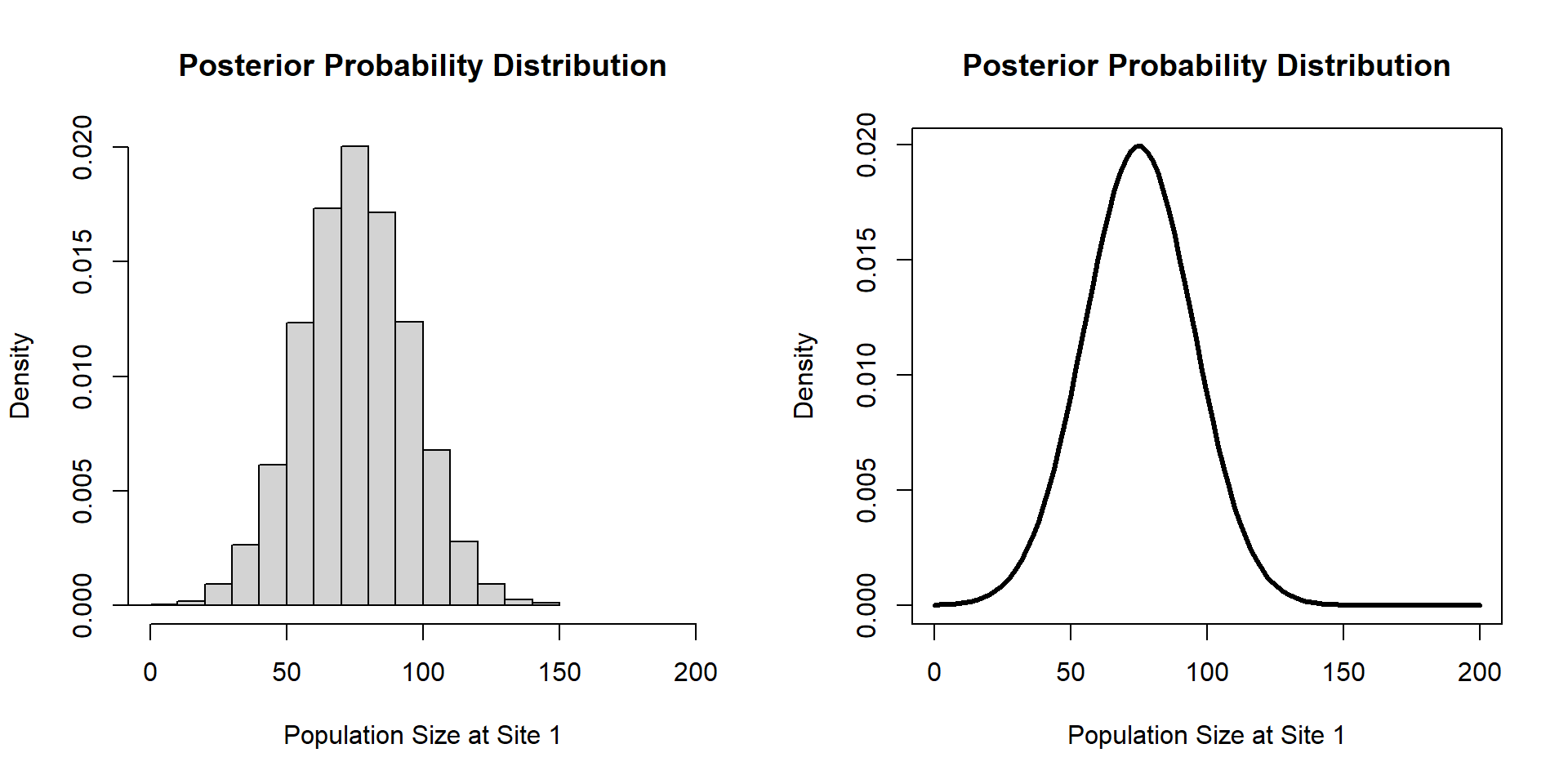
Bayesian Inference
Posterior Samples
Bayesian Inference
Posterior Samples
[1] 102.67671 81.11546 81.75260 87.77246 73.99043 80.70631 76.26219
[8] 83.99927 64.74208 26.93133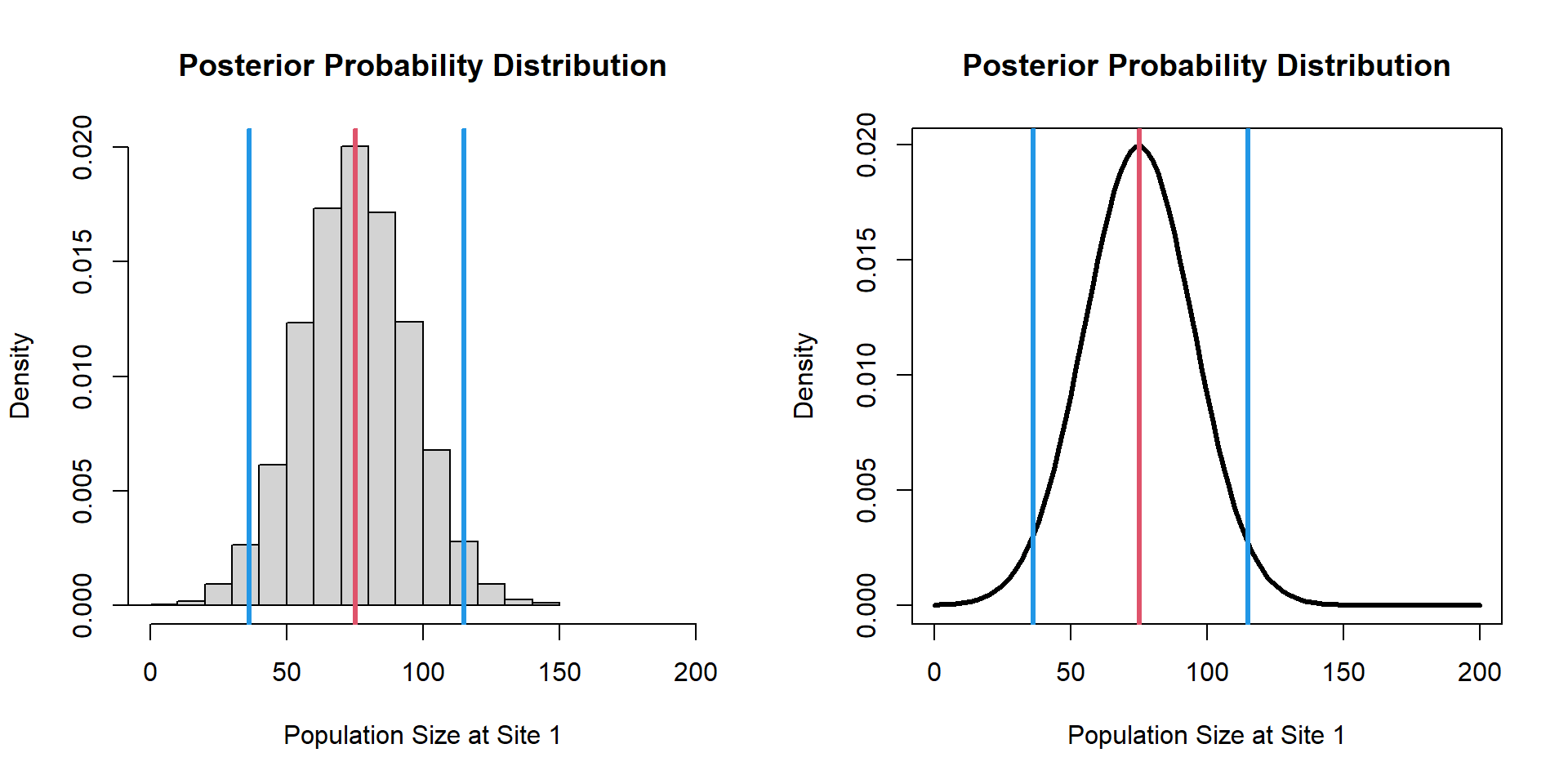
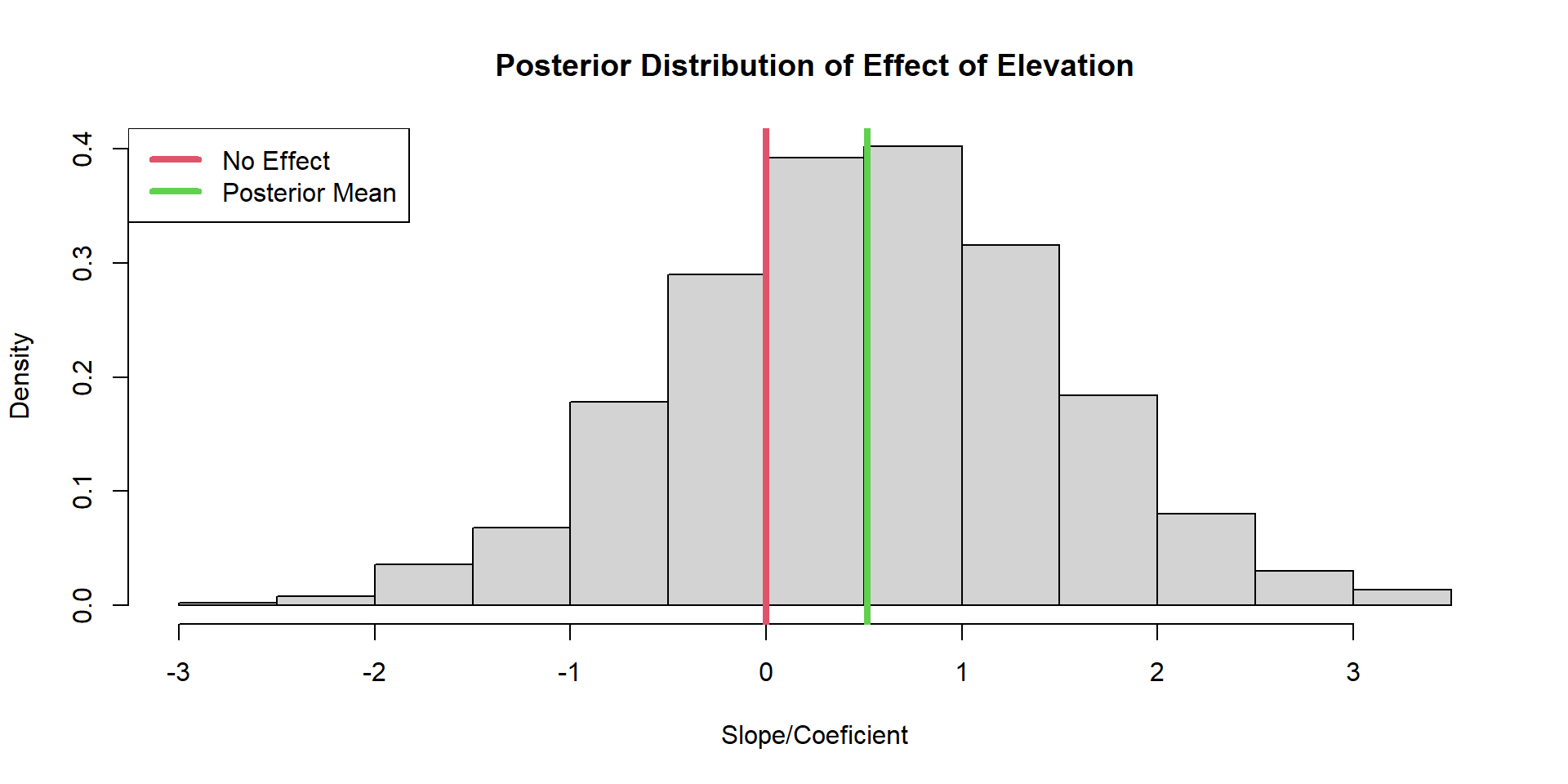
Bayesian Inference
Bayesian Inference (coeficient)
Bayes Theorem
Bayes Theorem
Bayes Theorem
Bayes Theorem
The Prior
All parameters in a Bayesian model require a prior specified; parameters are random variables.
\(y_{i} \sim \text{Binom}(N, \theta)\)
\(\theta \sim \text{Beta}(\alpha = 4, \beta=2)\)
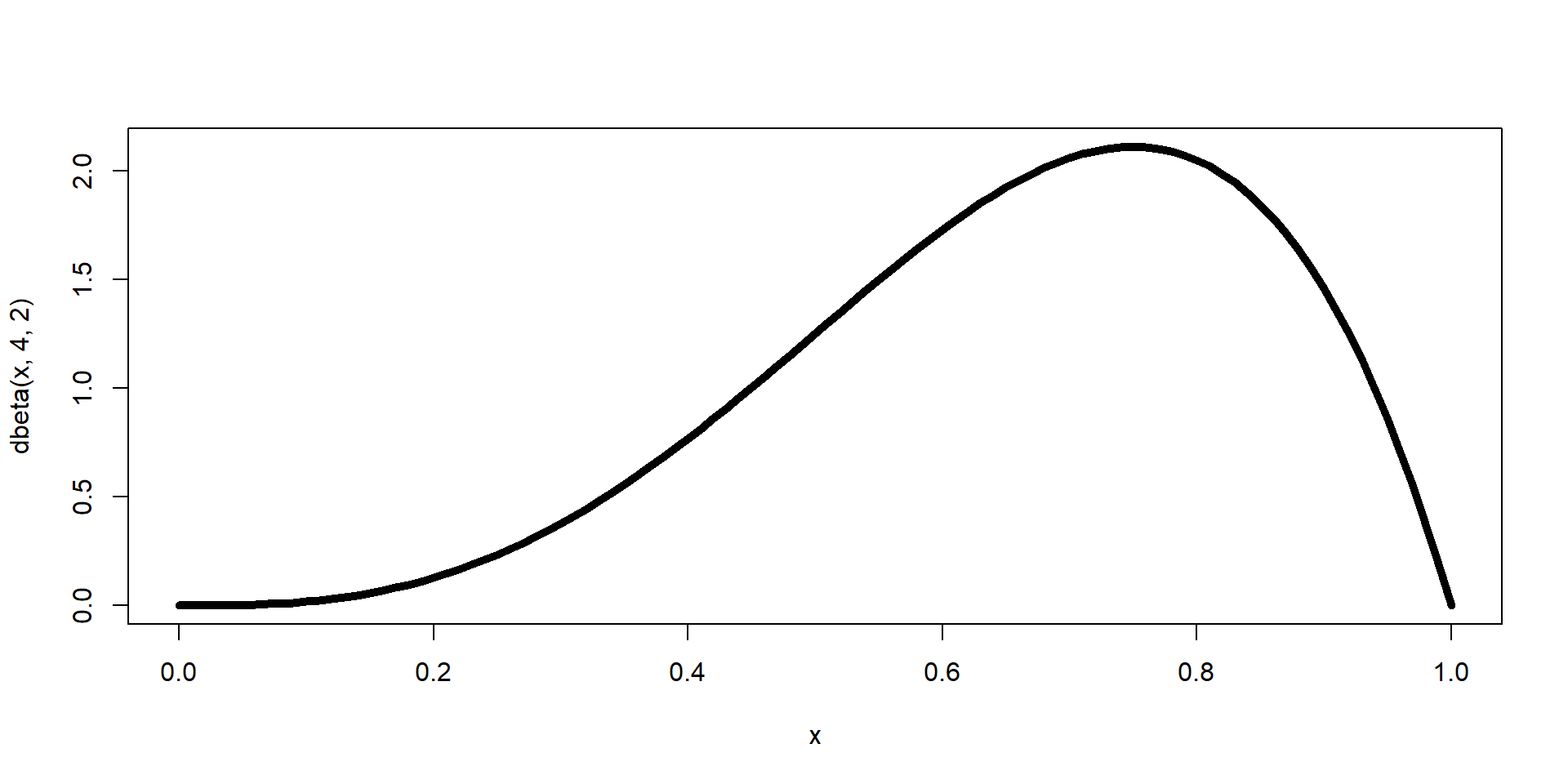
The Prior
\(\theta \sim \text{Beta}(\alpha = 1, \beta=1)\)
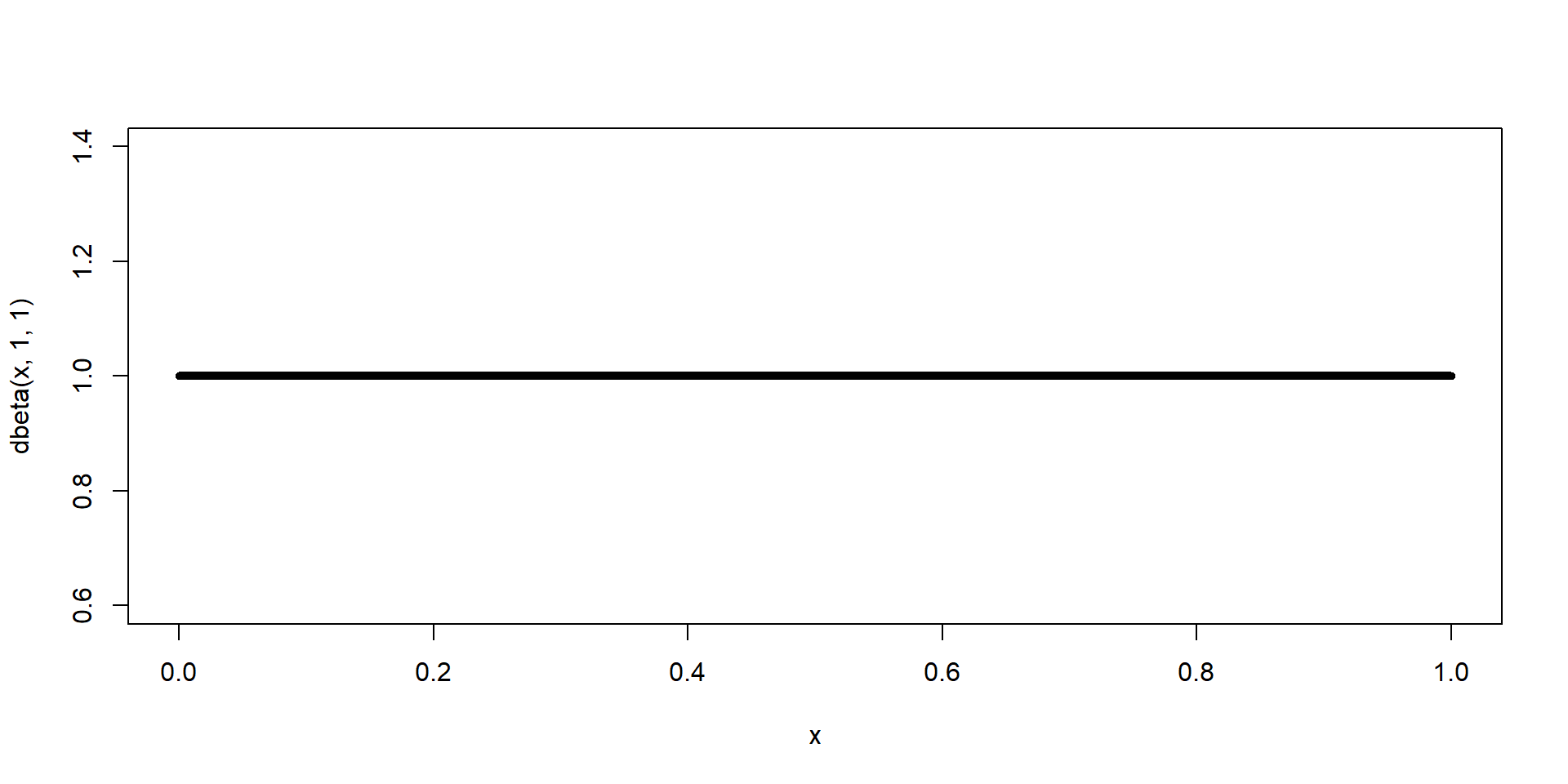
Bayesian Model
Model
\[ \textbf{y} \sim \text{Bernoulli}(p) \]
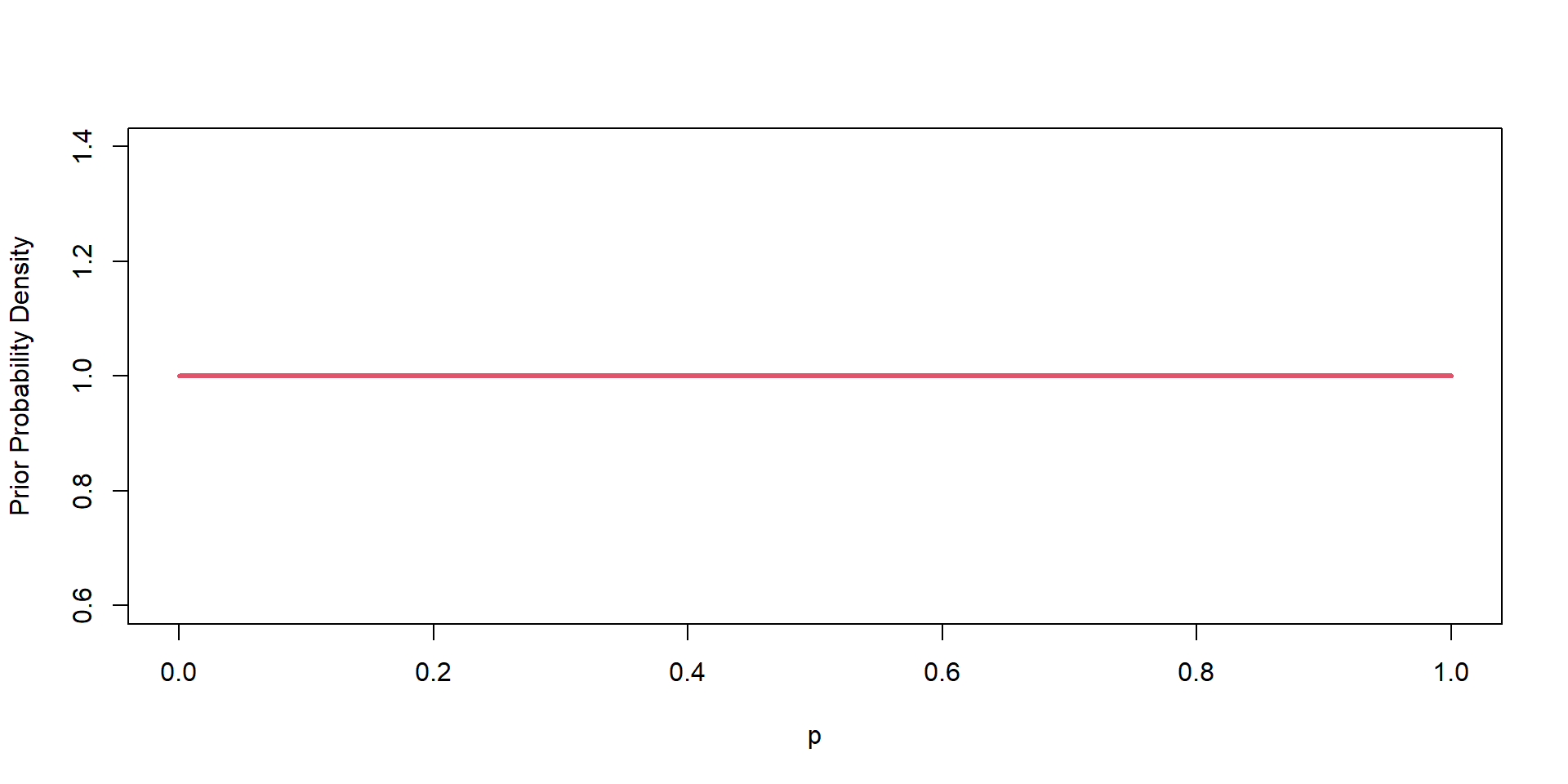
Hippos
We do a small study on hippo survival and get these data…

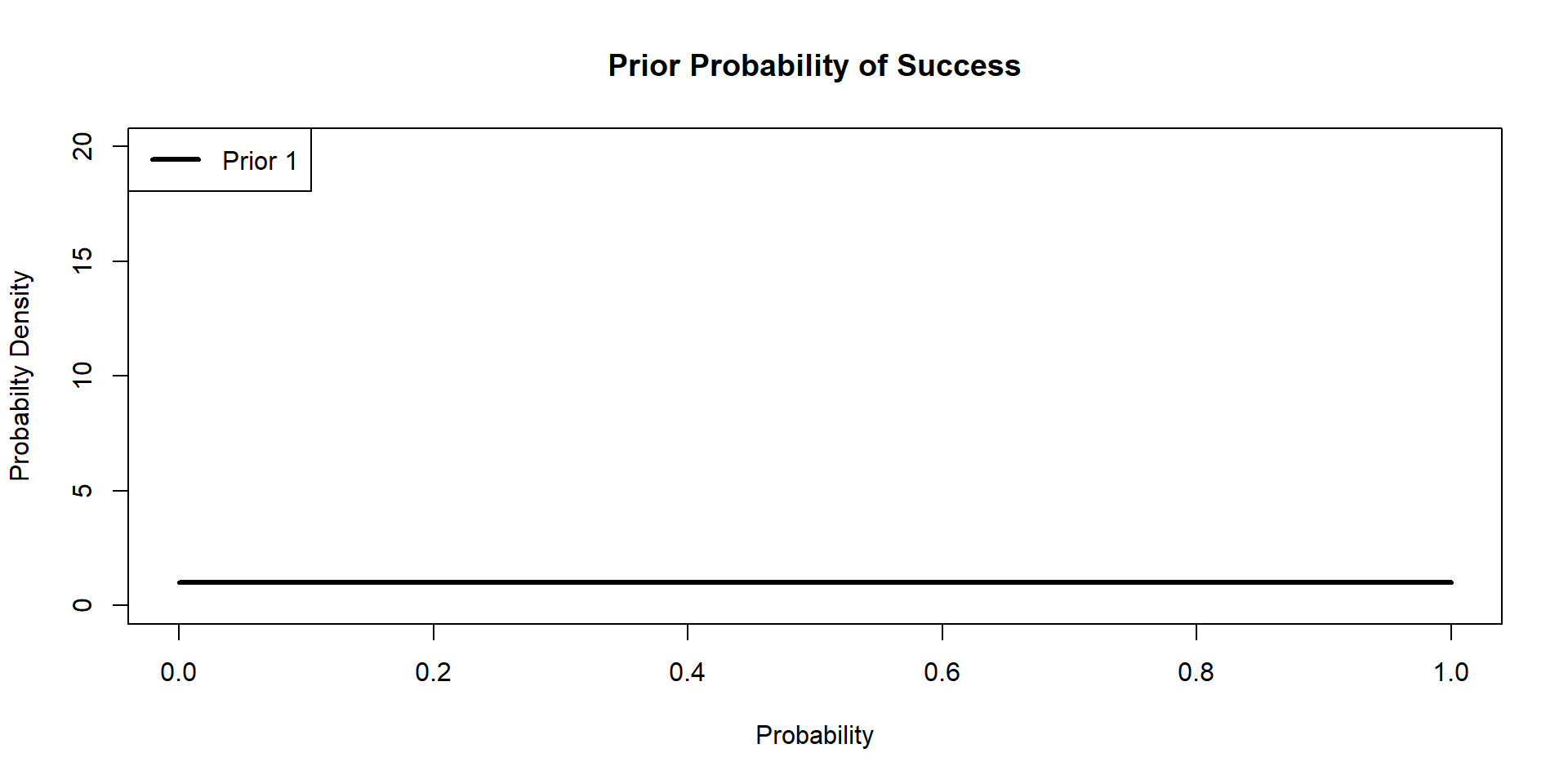
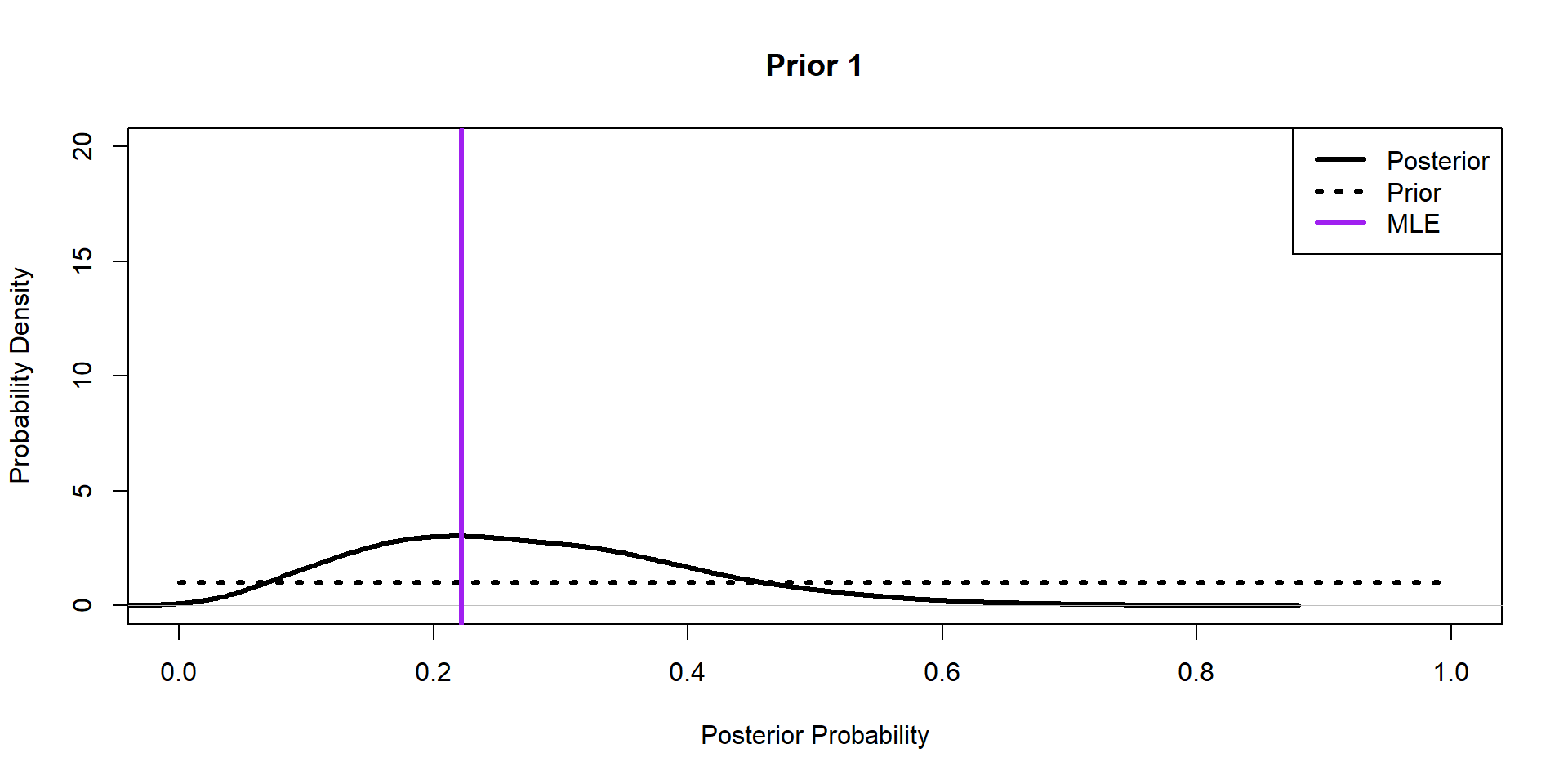
Hippos: Bayesian Model (Prior 1)
\[ \begin{align*} \textbf{y} \sim& \text{Binomial}(N,p)\\ p \sim& \text{Beta}(\alpha,\beta) \end{align*} \]
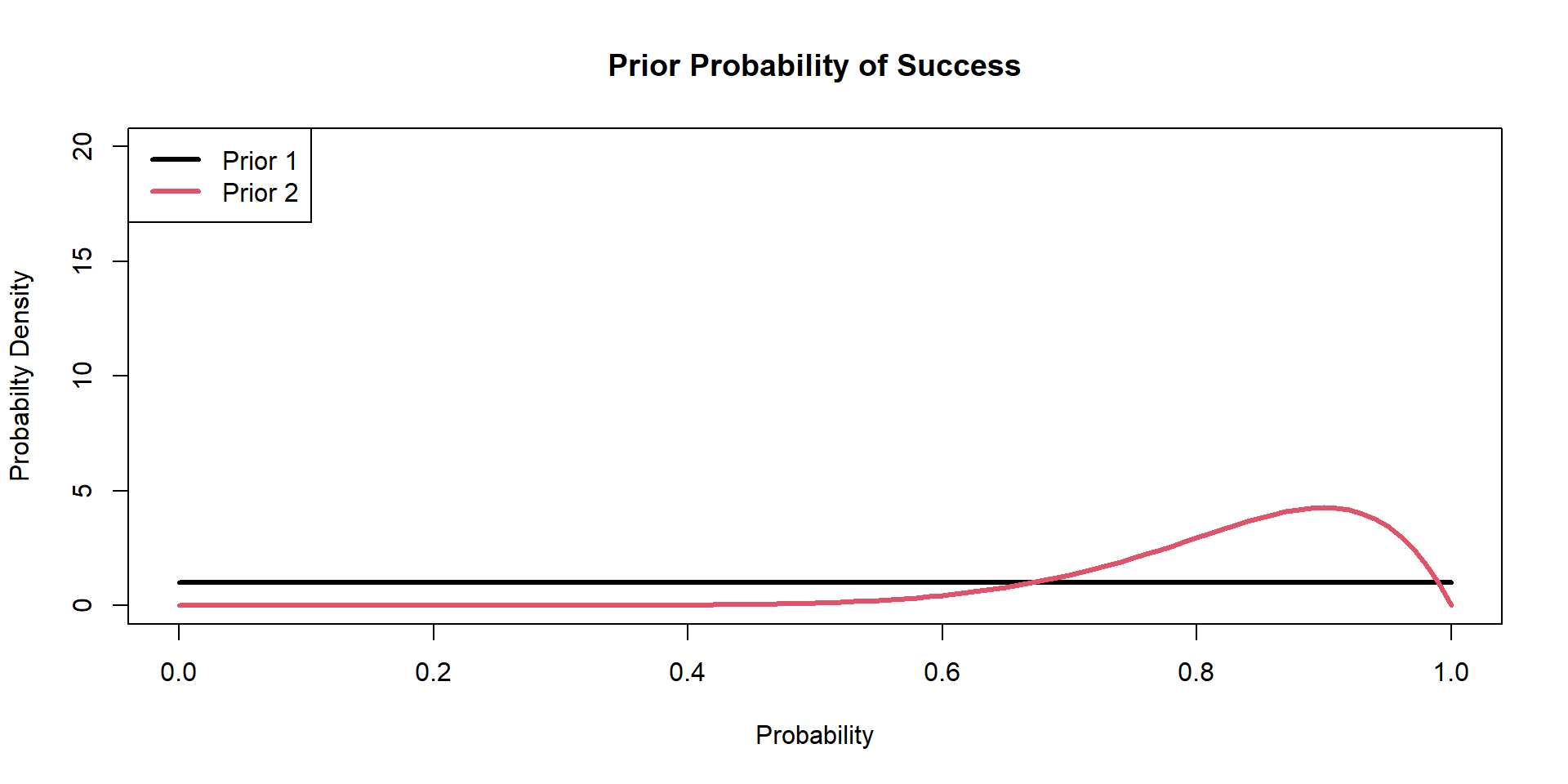
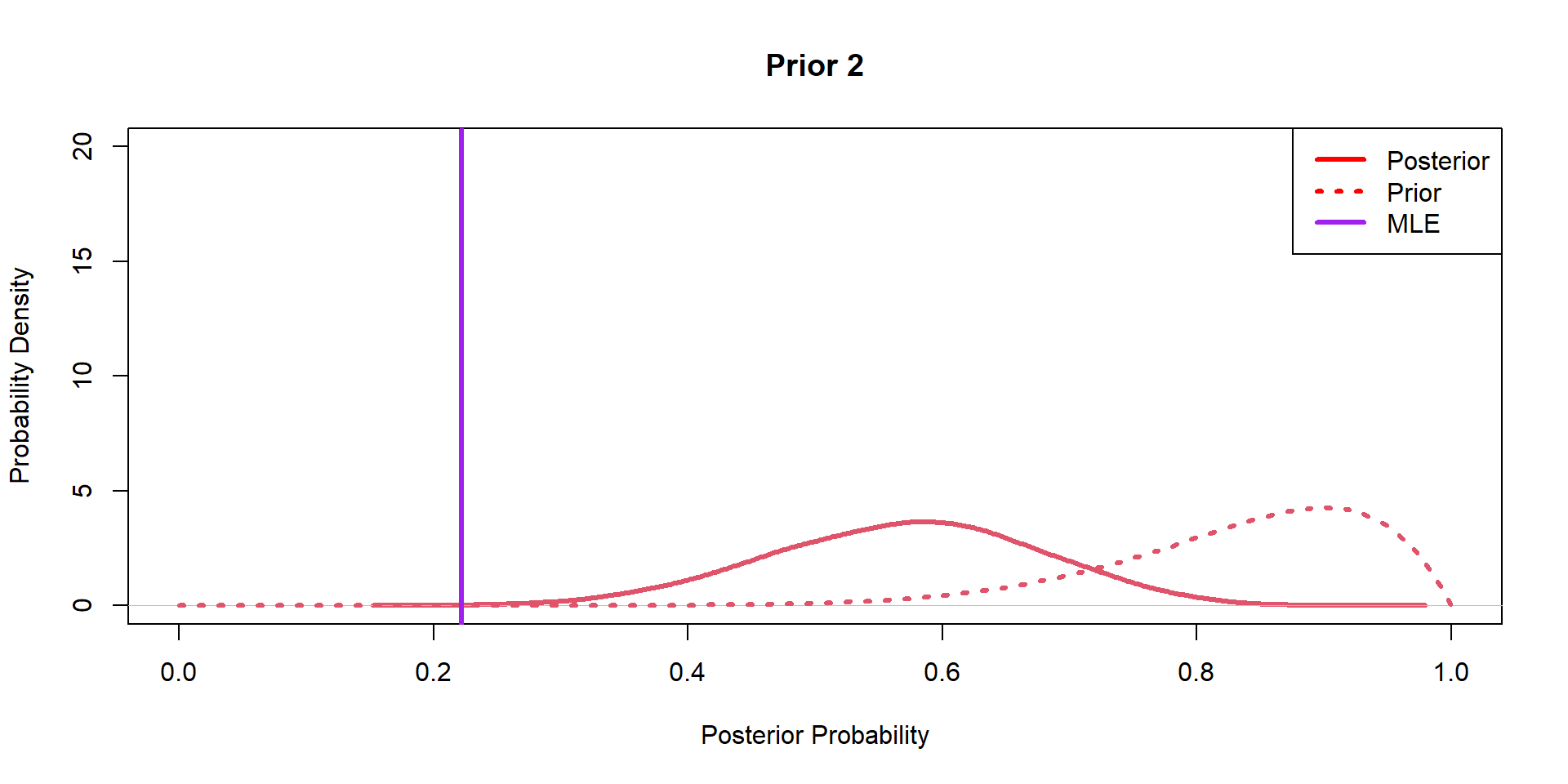
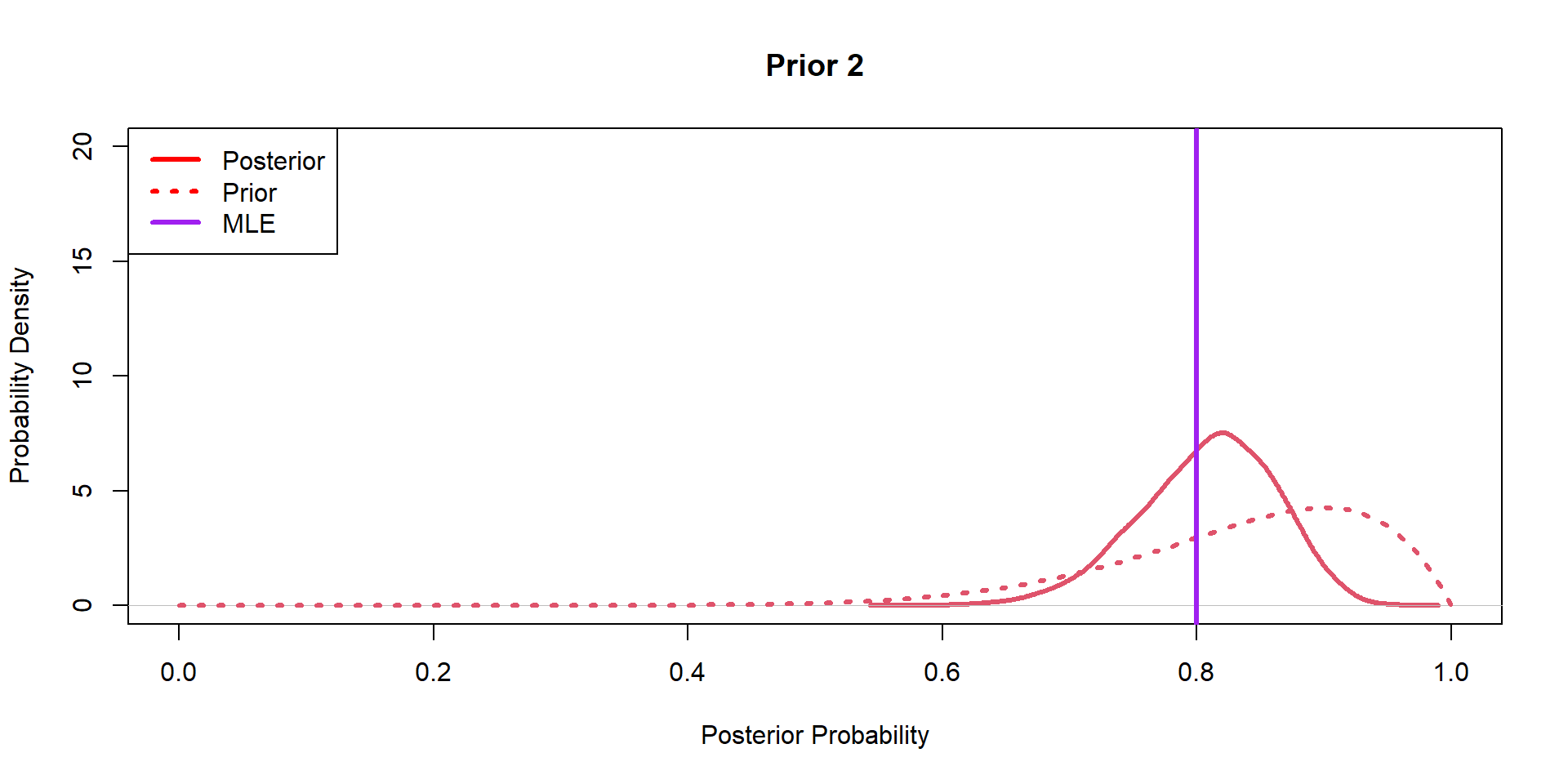
Hippos: Bayesian Model (Prior 2)
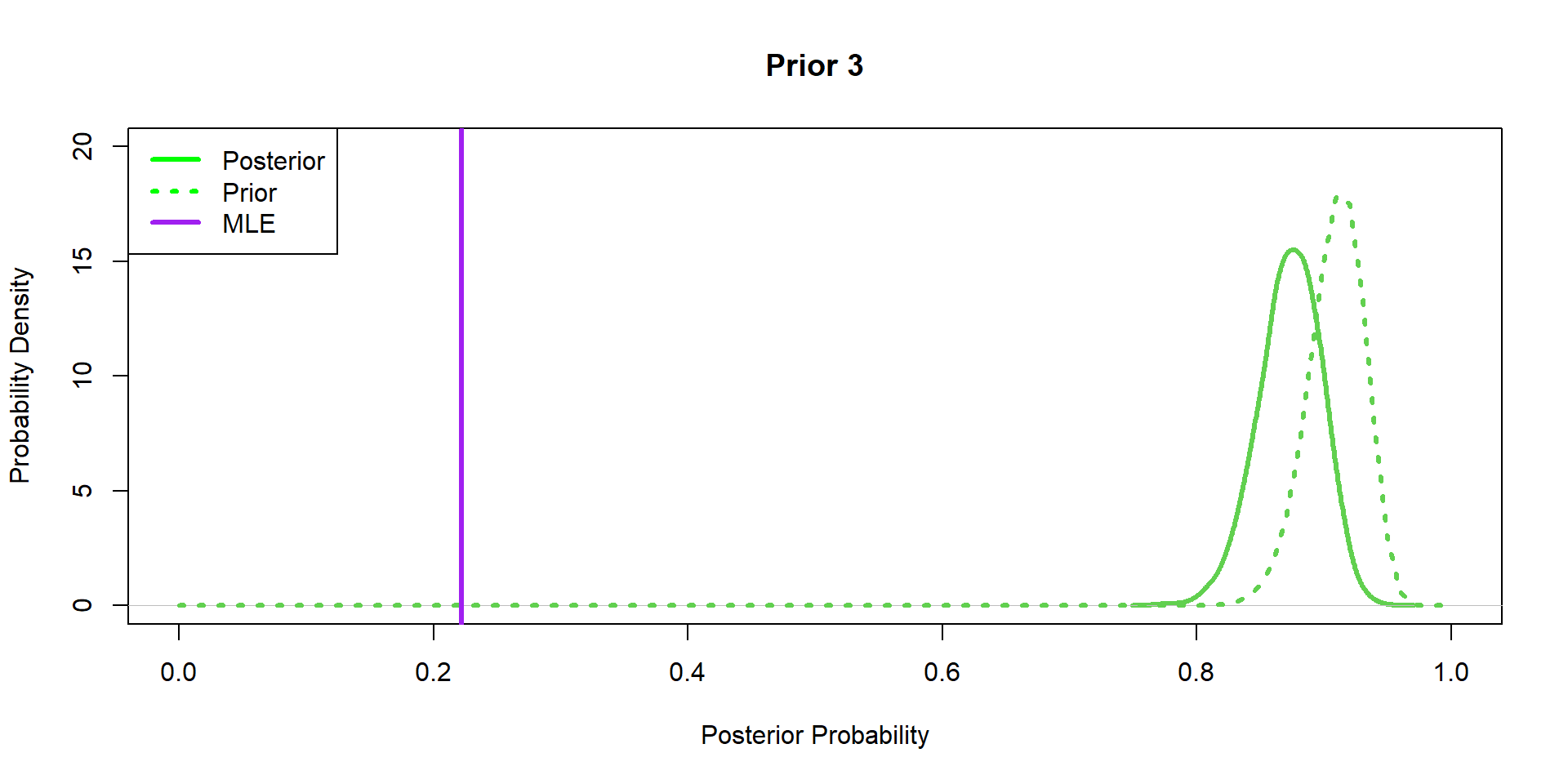
Hippos: Bayesian Model (Prior 3)
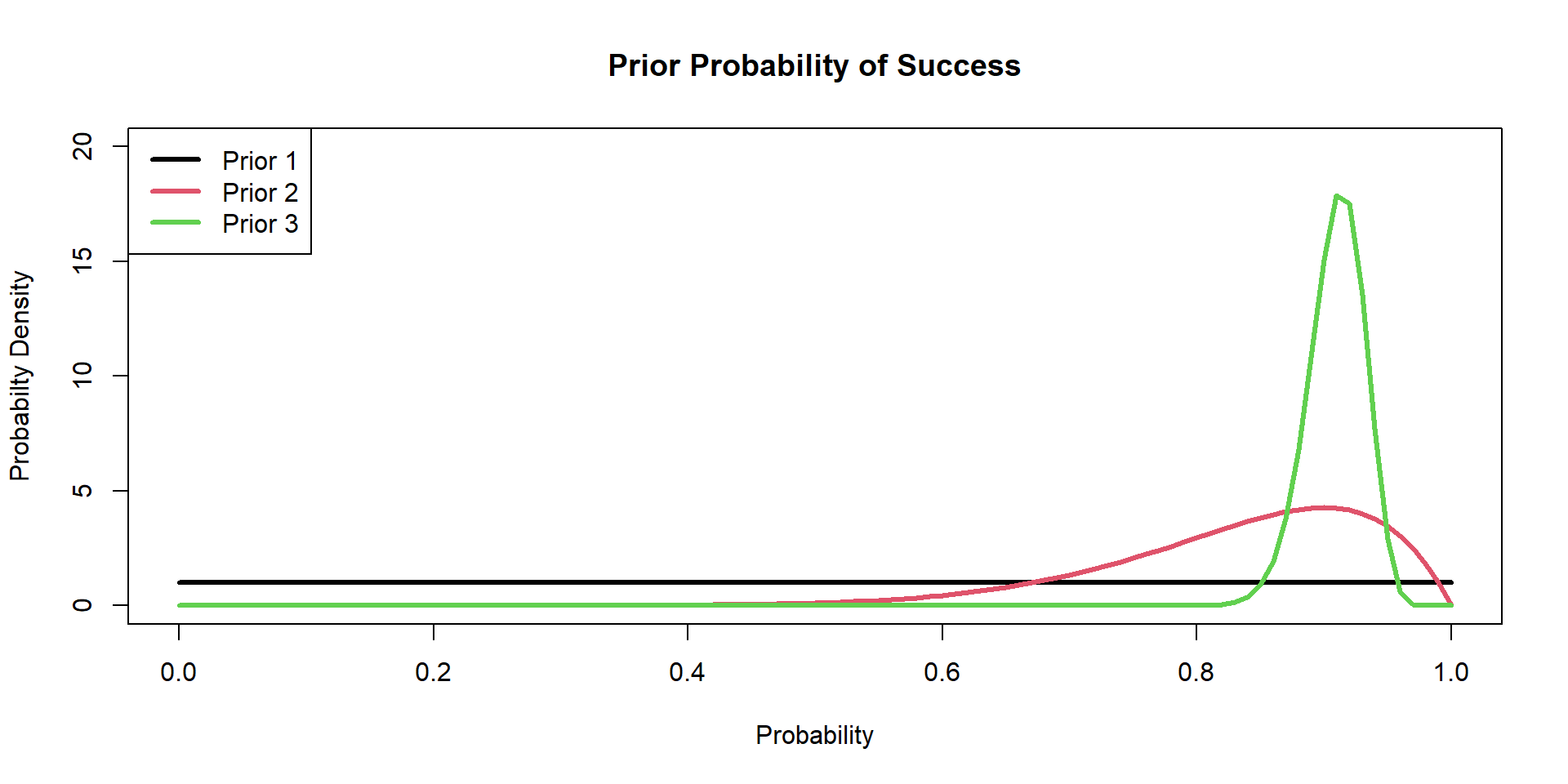
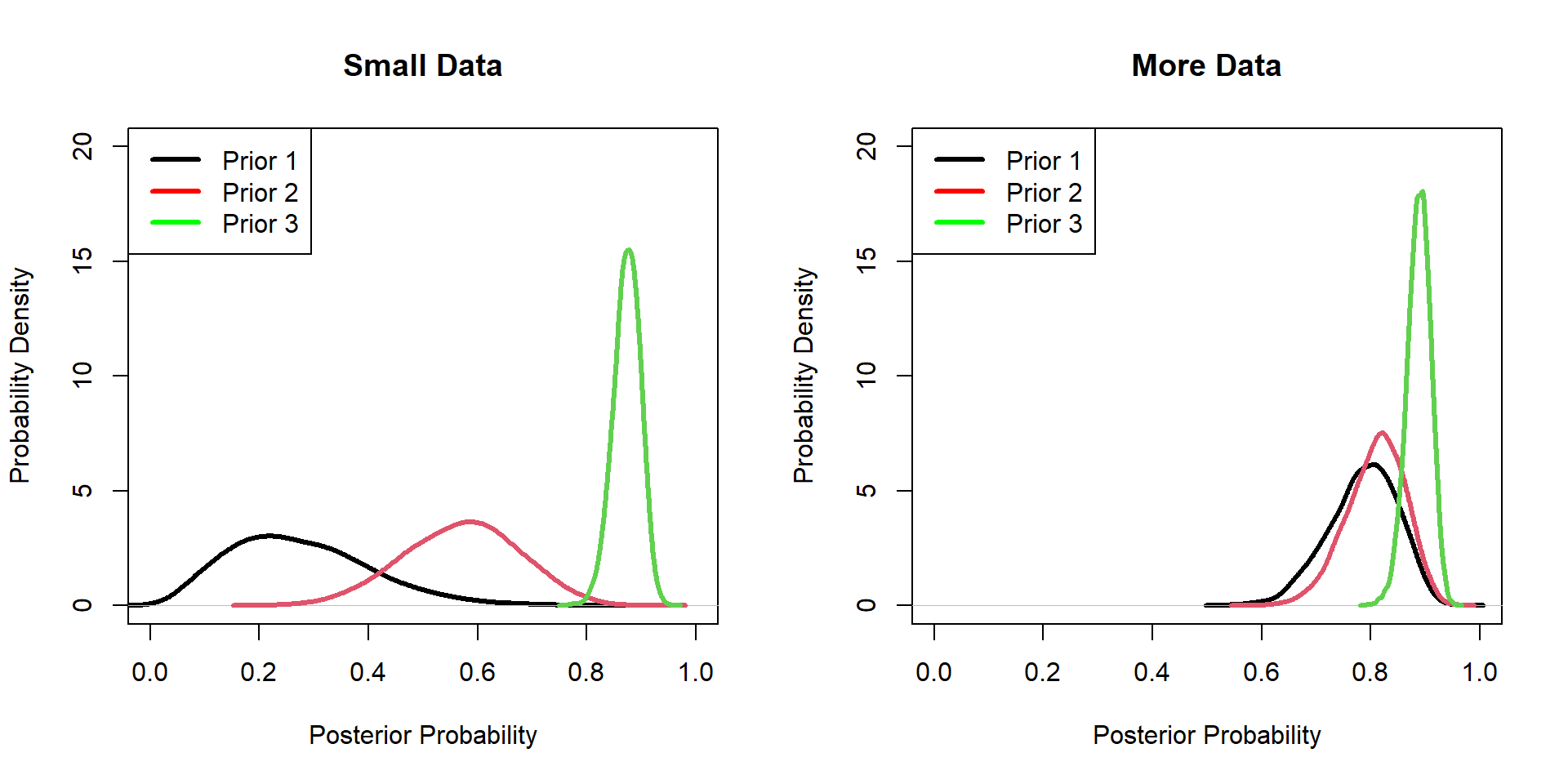
Hippos: Bayesian Model (Posteriors)
Hippos: Bayesian Model (Posteriors)
Hippos: Bayesian Model (Posteriors)
Hippos: More data! (Prior 1)
[1] 40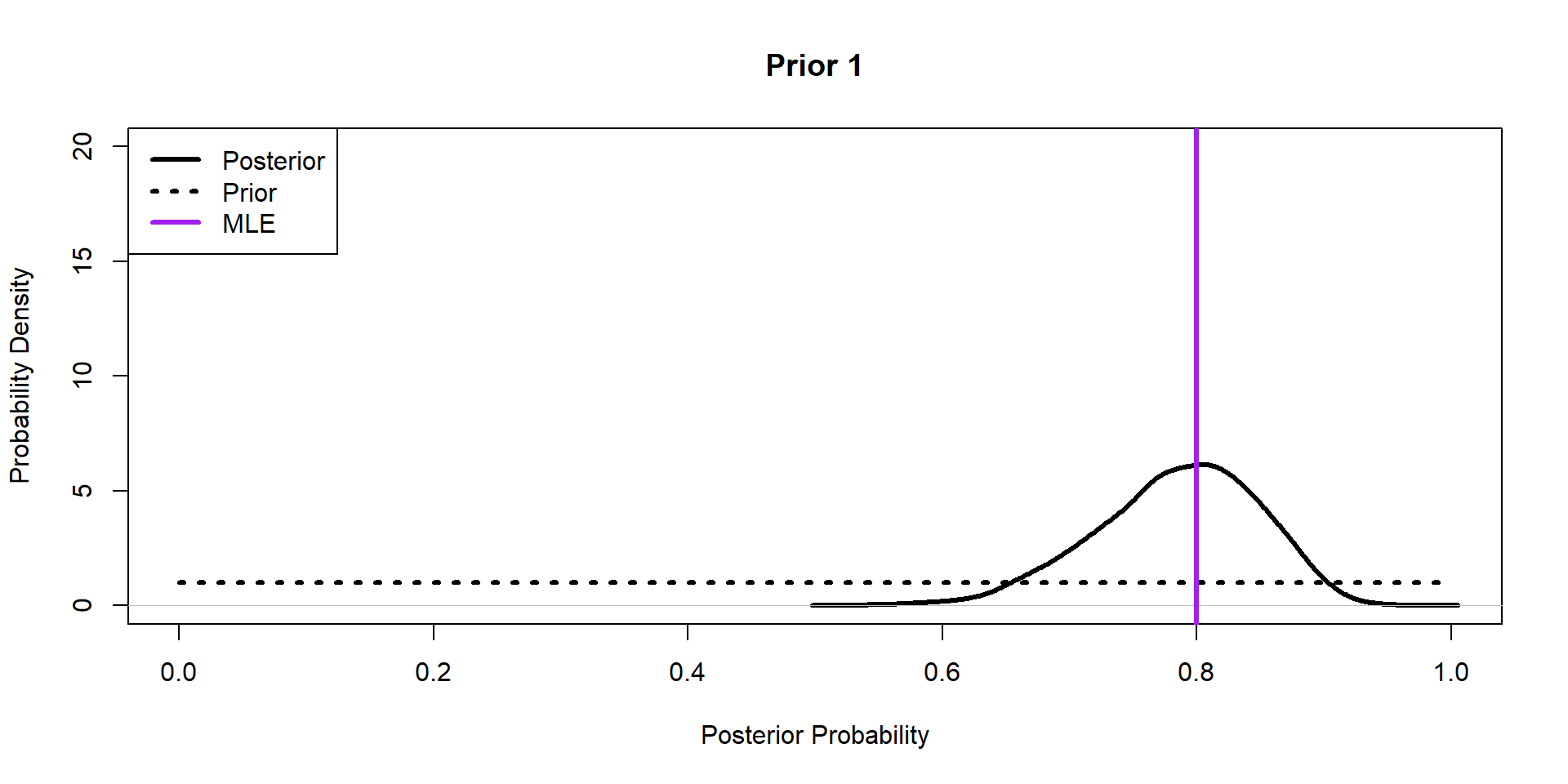
Hippos: More data! (Prior 2)
Hippos: More data! (Prior 3)
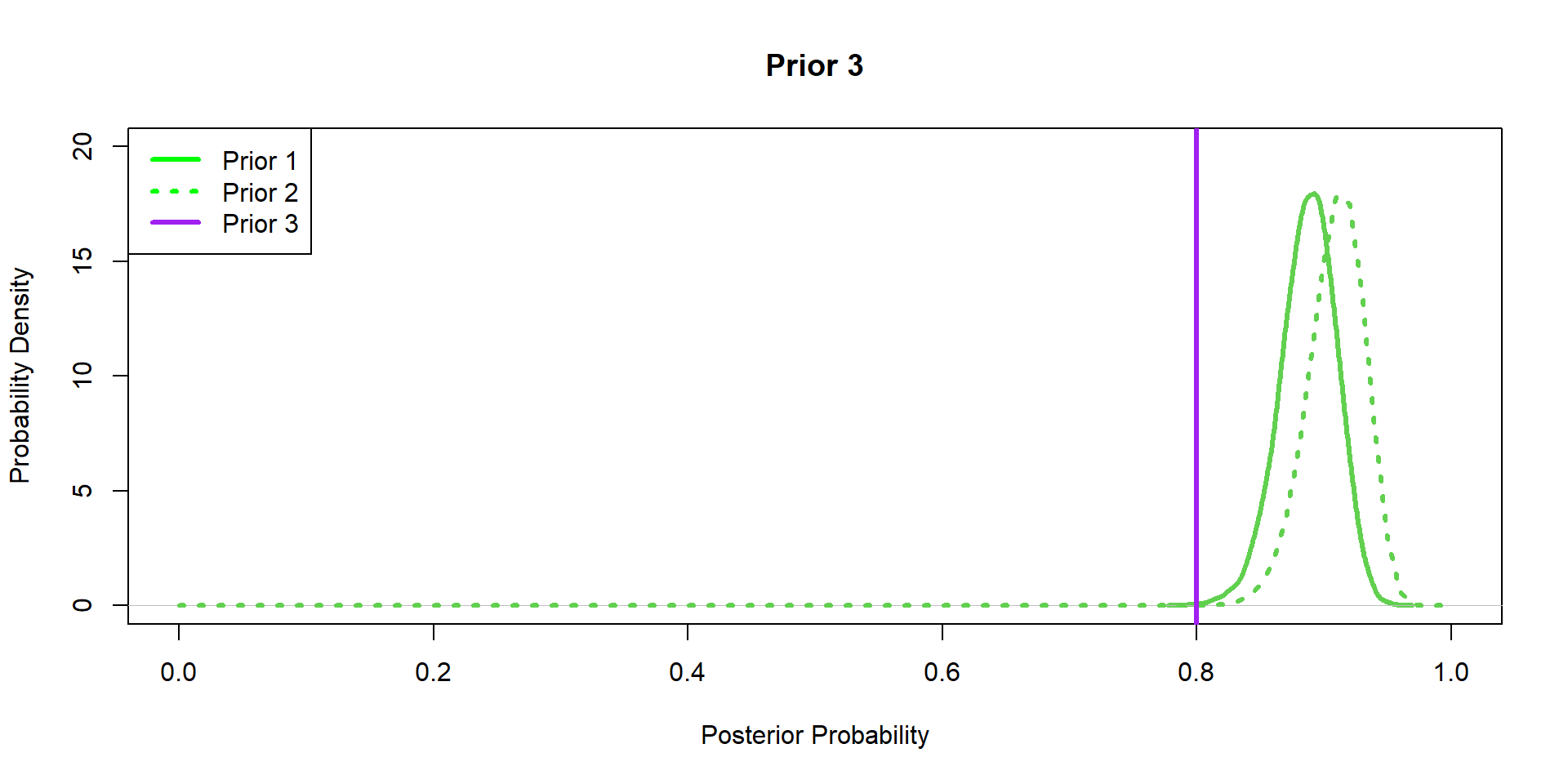
Hippos: Data/prior Comparison