Connect random variables, probabilities, and parameters
define prob. functions
discrete and continuous random variables
use/plot prob. functions
learn some notation
Probability/Statistics
Probability and statistics are the opposite sides of the same coin.
To understand statistics, we need to understand probability and probability functions.
The two key things to understand this connection is the random variable (RV) and parameters (e.g., \(\theta\), \(\sigma\), \(\epsilon\), \(\mu\)).
Motivation
Why learn about RVs and probability math?
Foundations of:
linear regression
generalized linear models
mixed models
Our Goal:
conceptual framework to think about data, probabilities, and parameters
mathematical connections and notation
Not Random Variables
\[
\begin{align*}
a =& 10 \\
b =& \text{log}(a) \times 12 \\
c =& \frac{a}{b} \\
y =& \beta_0 + \beta_1*c
\end{align*}
\]
All variables here are scalars. They are what they are and that is it. \(\beta\) variables and \(y\) are currently unknown, but still scalars.
Scalars are quantities that are fully described by a magnitude (or numerical value) alone.
Random Variables
\[
y \sim f(y)
\]
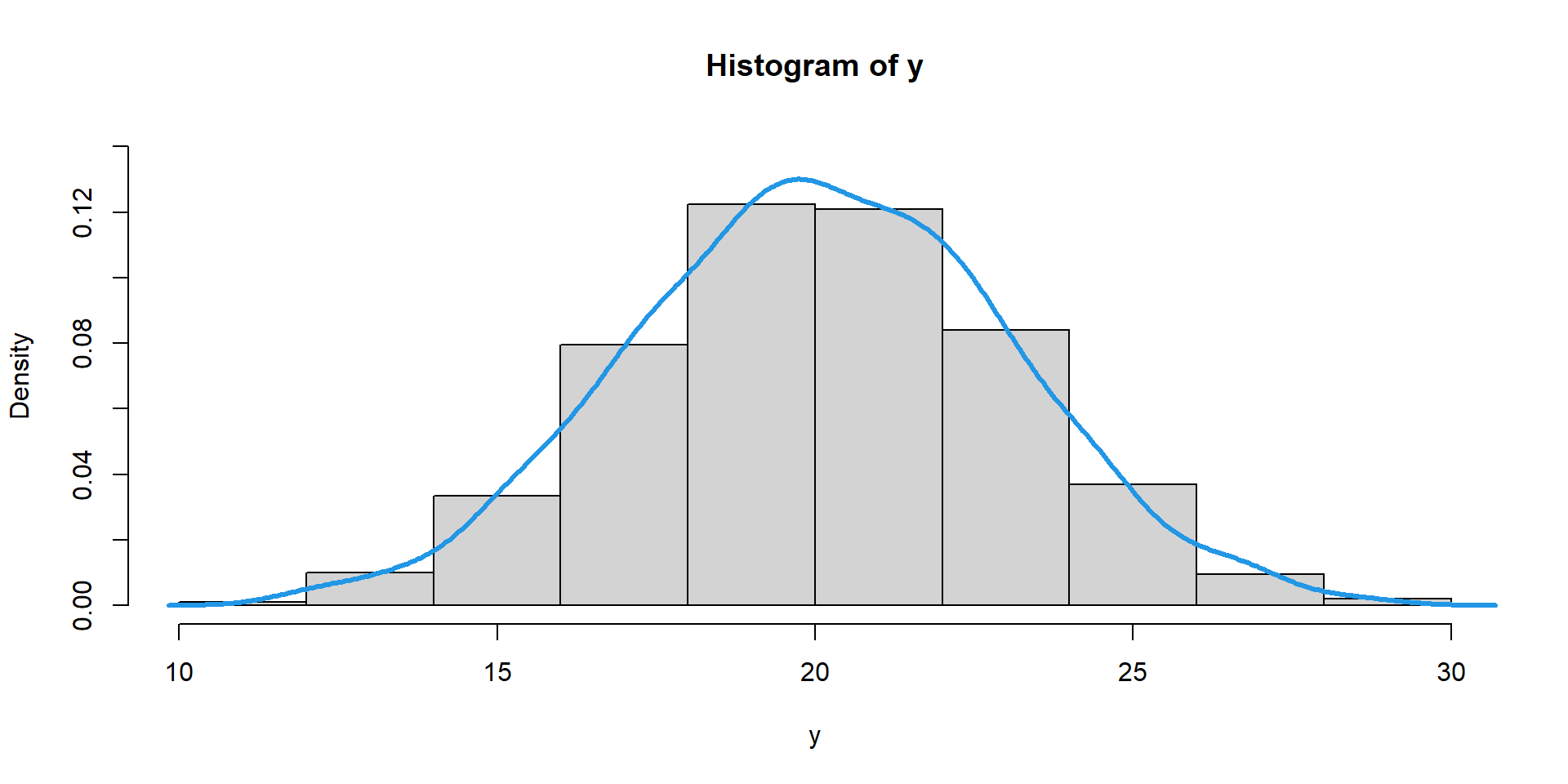
\(y\) is a random variable which may change values each observation; it changes based on a probability function, \(f(y)\).
The tilde (\(\sim\)) denotes “has the probability distribution of”.
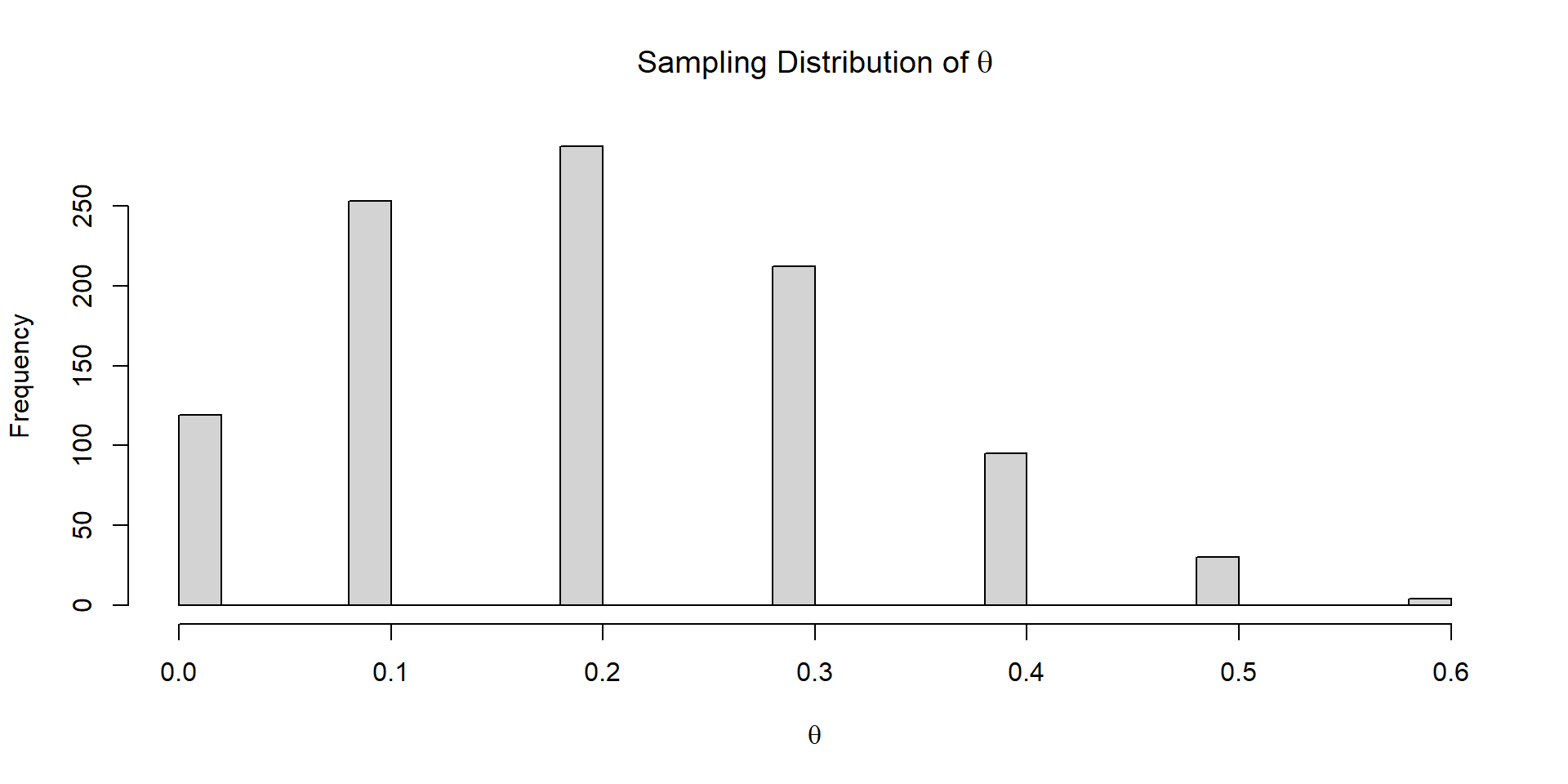
Which value (y) is observed is predictable. Need to know parameters (\(\theta\)) of the probability function \(f(y)\).
Specifically, \(f(y|\theta)\), where ‘|’ is read as ‘given’.
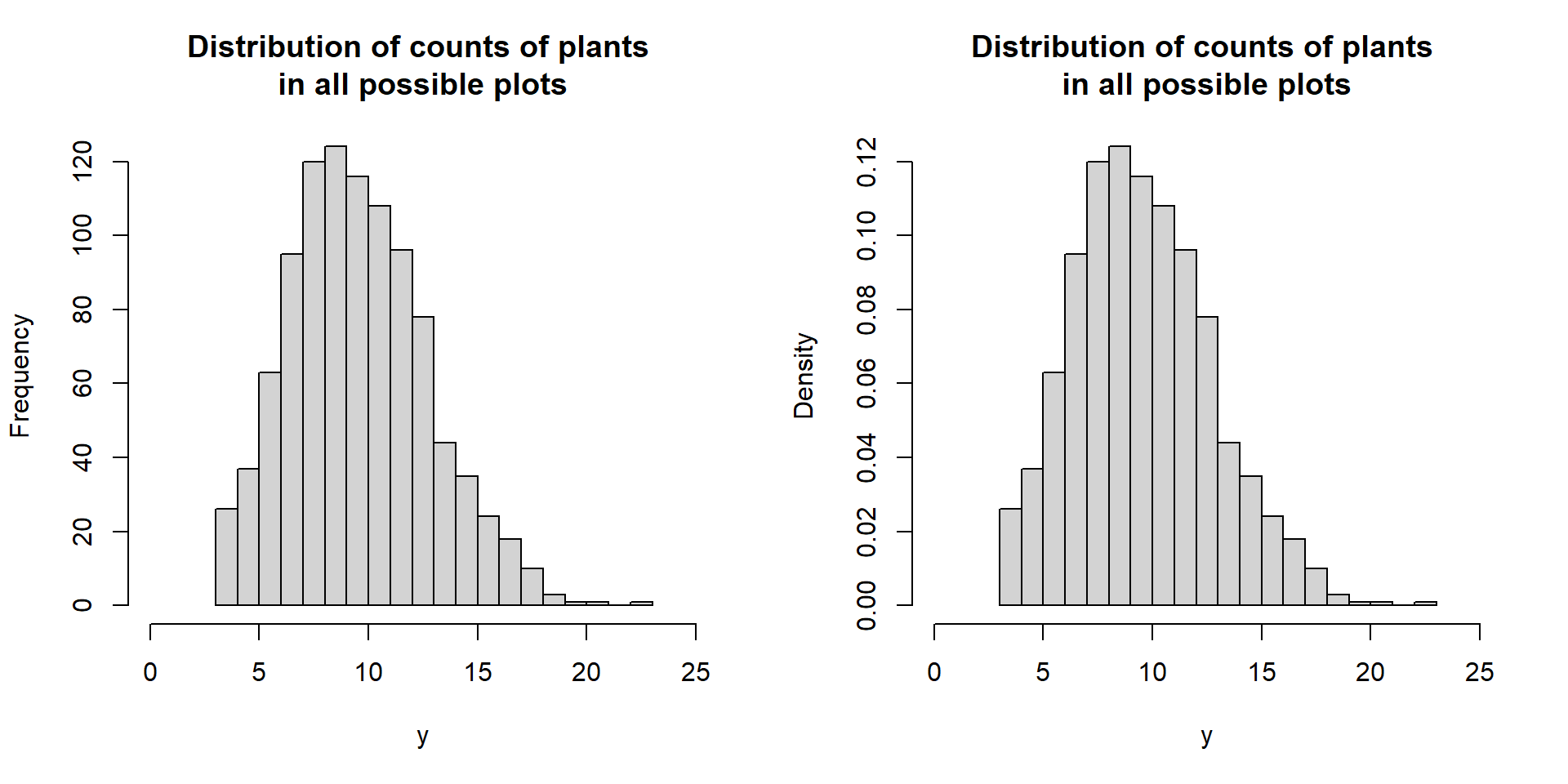
Toss of a coin Roll of a die Weight of a captured elk Count of plants in a sampled plot
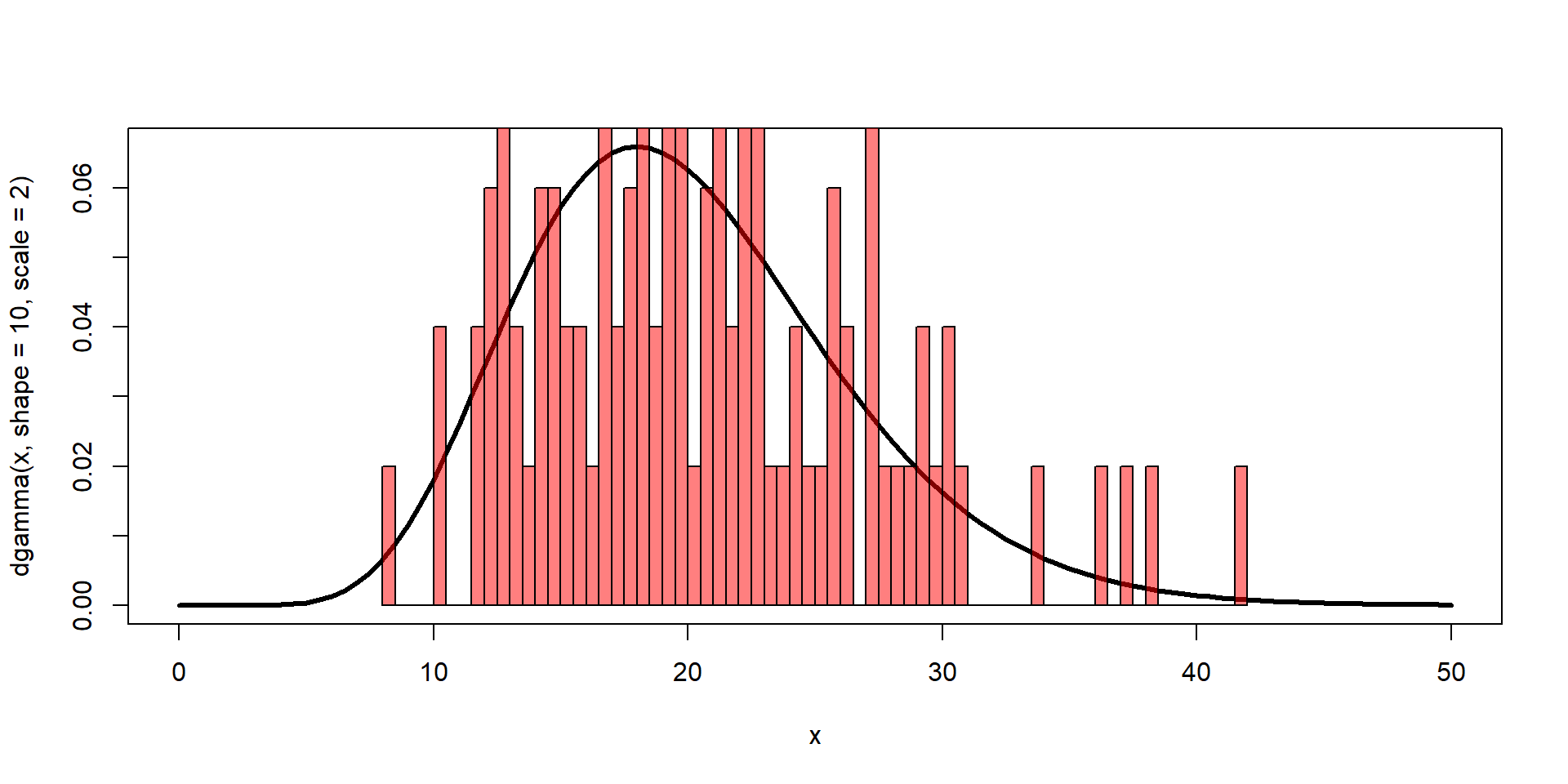
The values observed can be understand based on the frequency within the population or presumed super-population. These frequencies can be described by probabilities.
We often only get to see ONE sample from this distribution.
Random Variables
We are often interested in the characteristics of the whole population of frequencies,
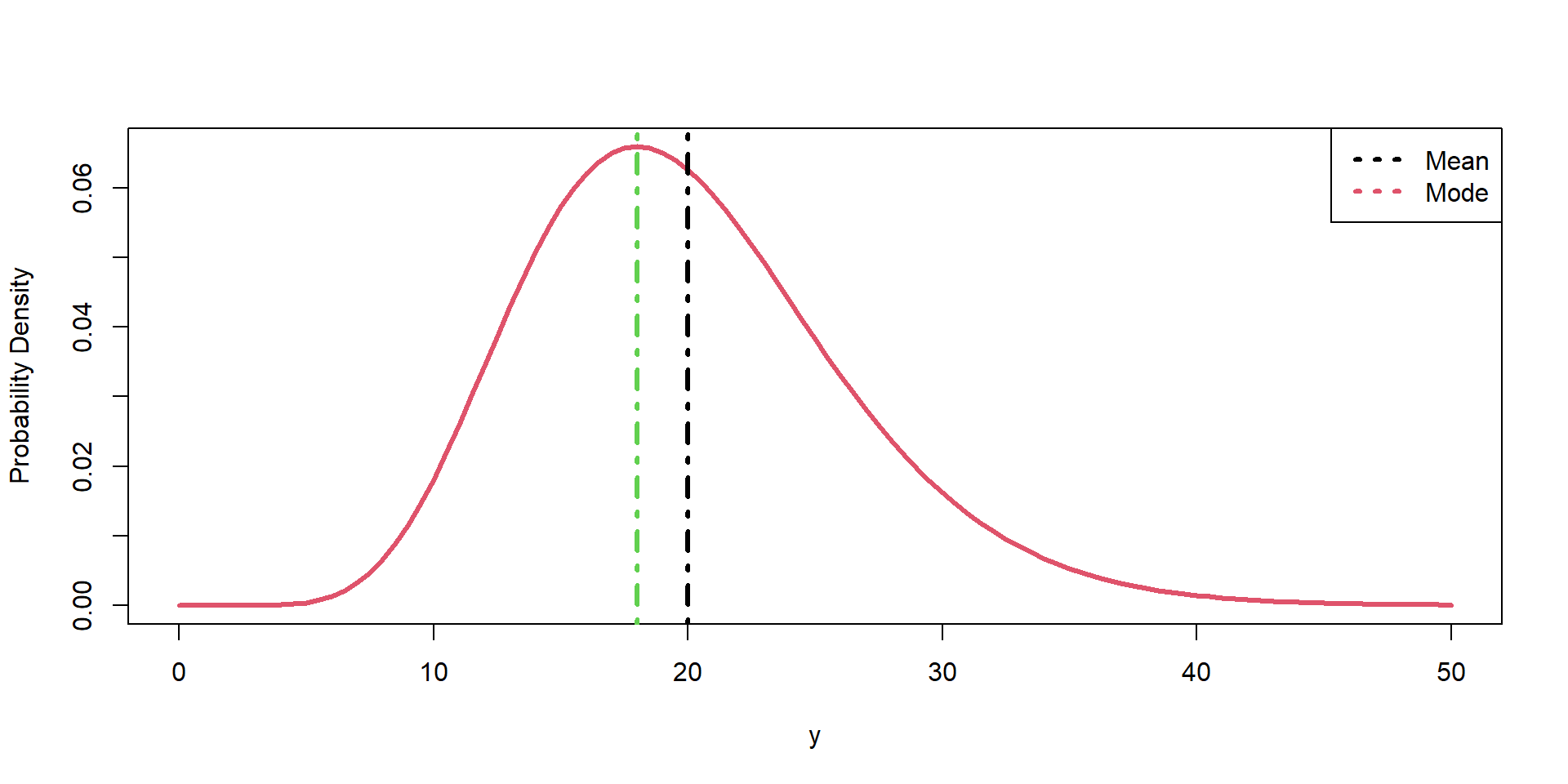
central tendency (mean, mode, median)
variability (var, sd)
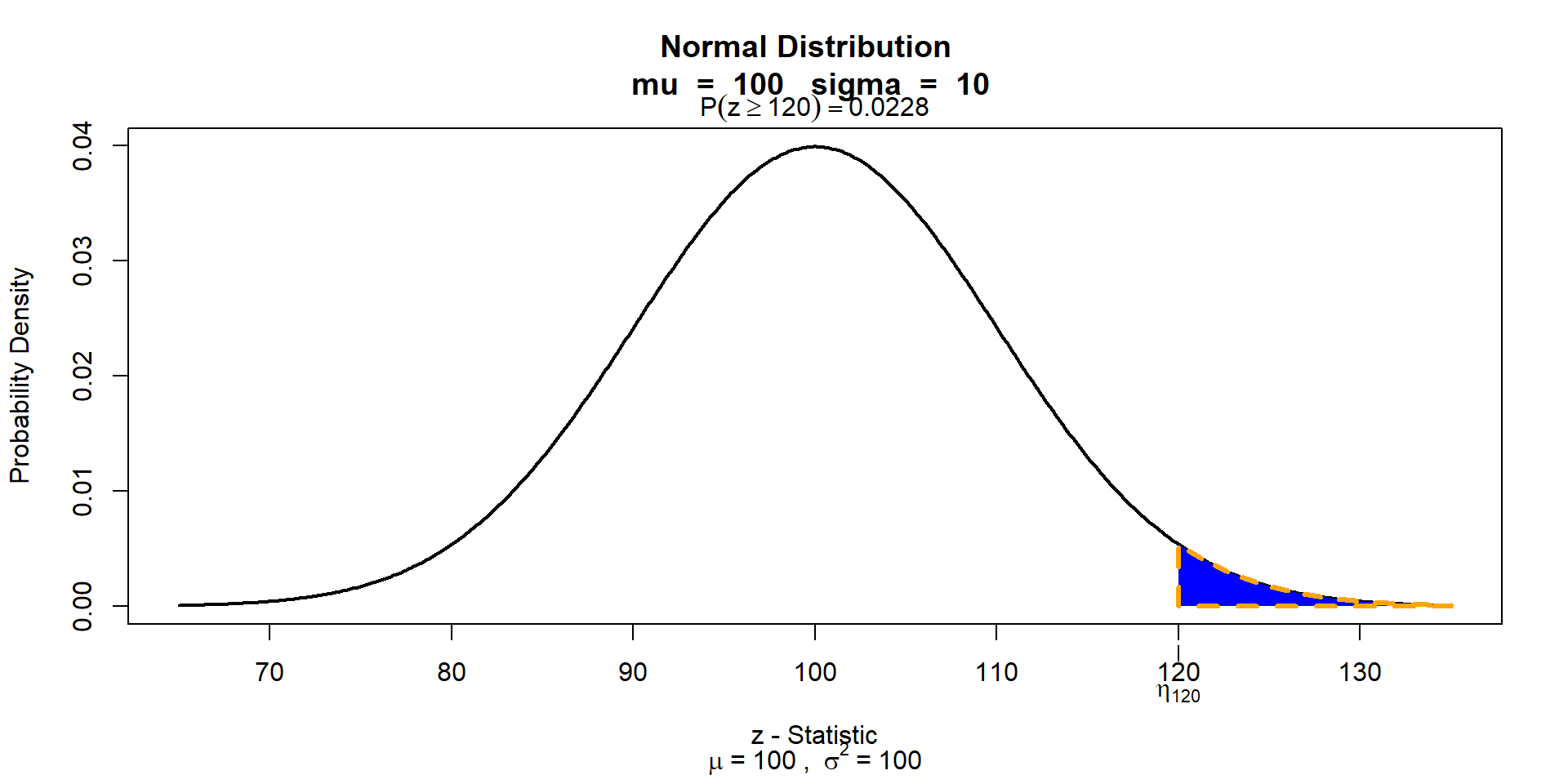
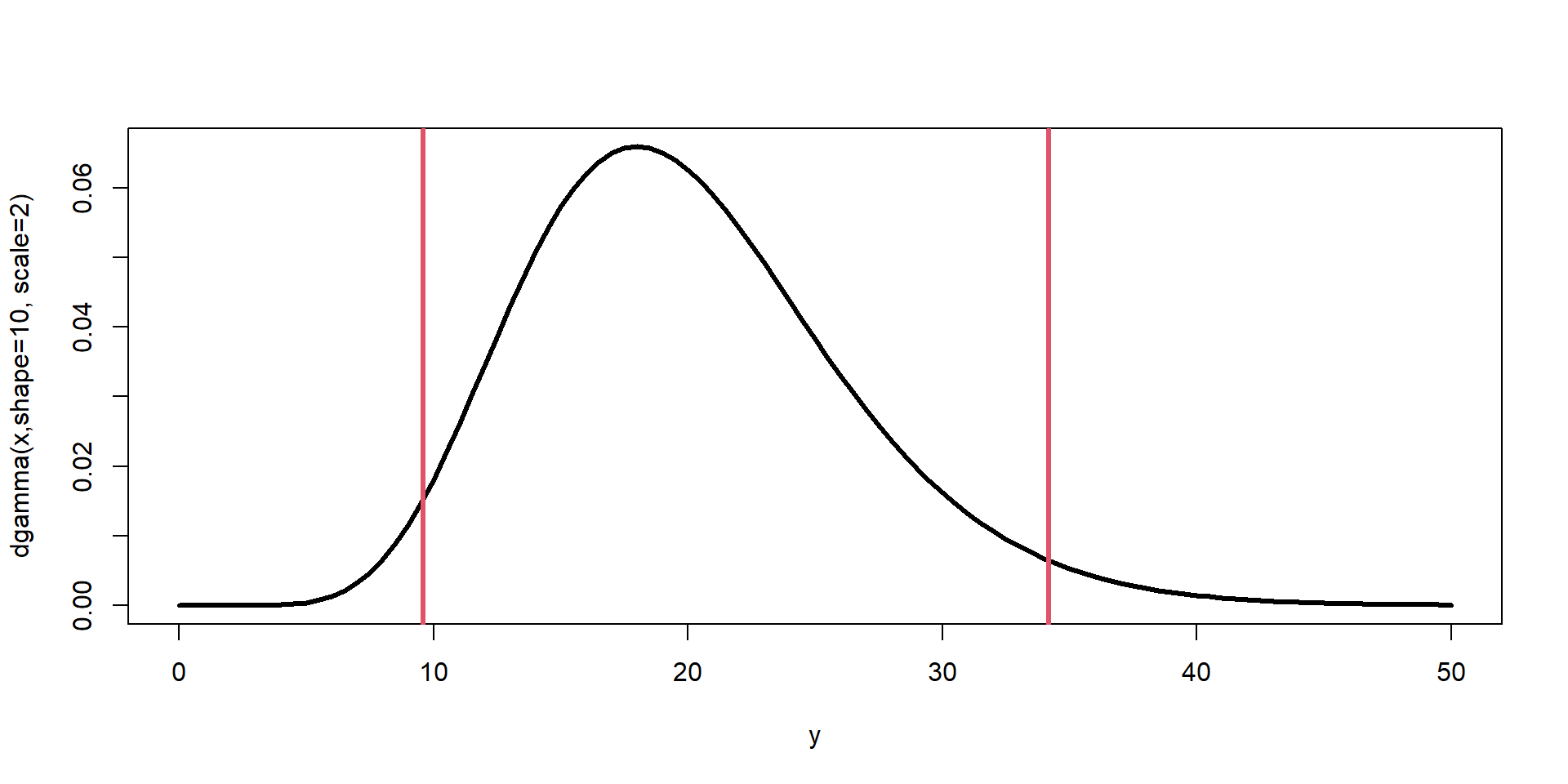
proportion of the population that meets some condition P(\(8 \leq y \leq\) 12) =0.68
We infer what these are based on our sample (i.e., statistical inference).
Philosophy
Frequentist Paradigm:
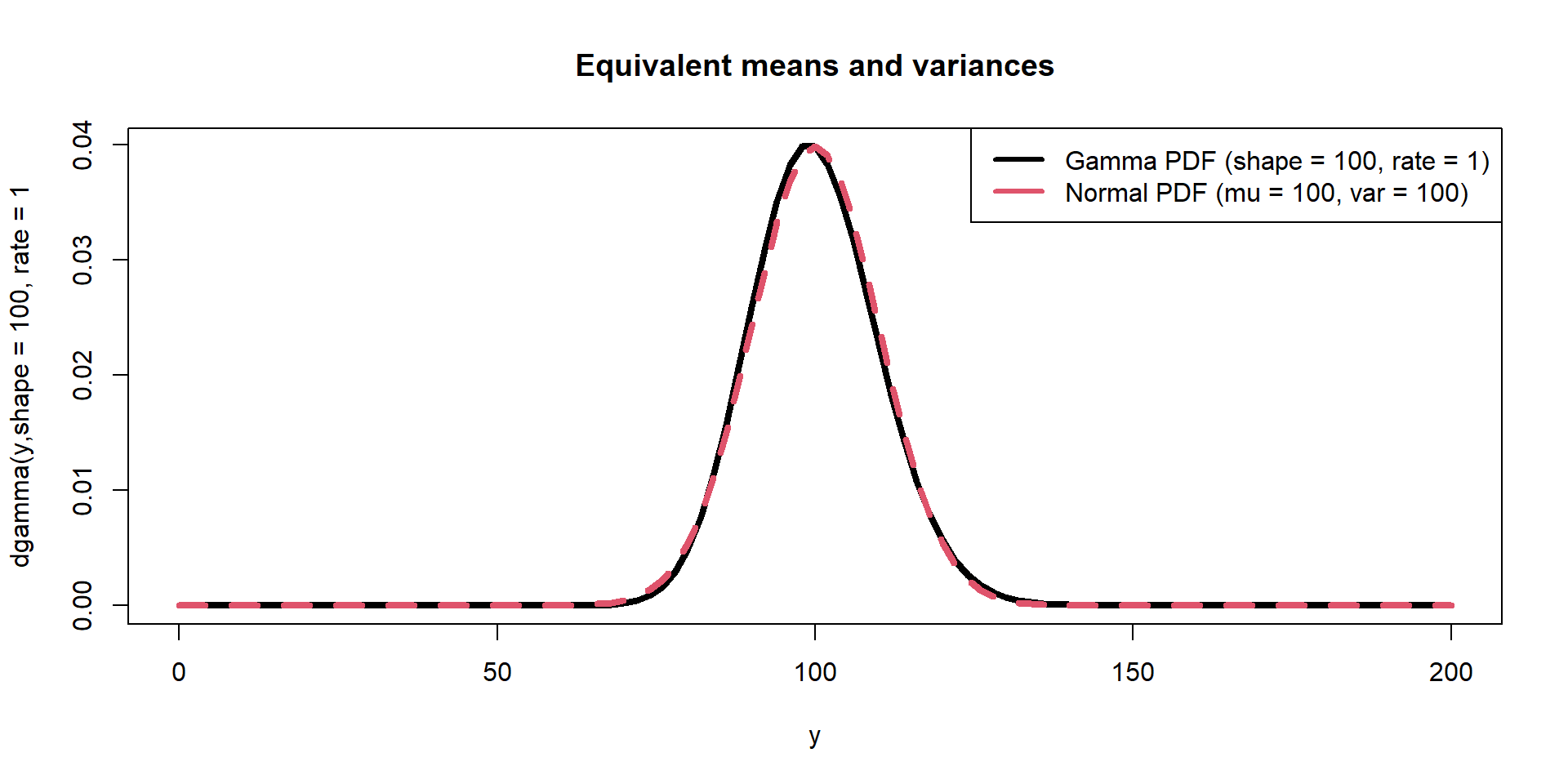
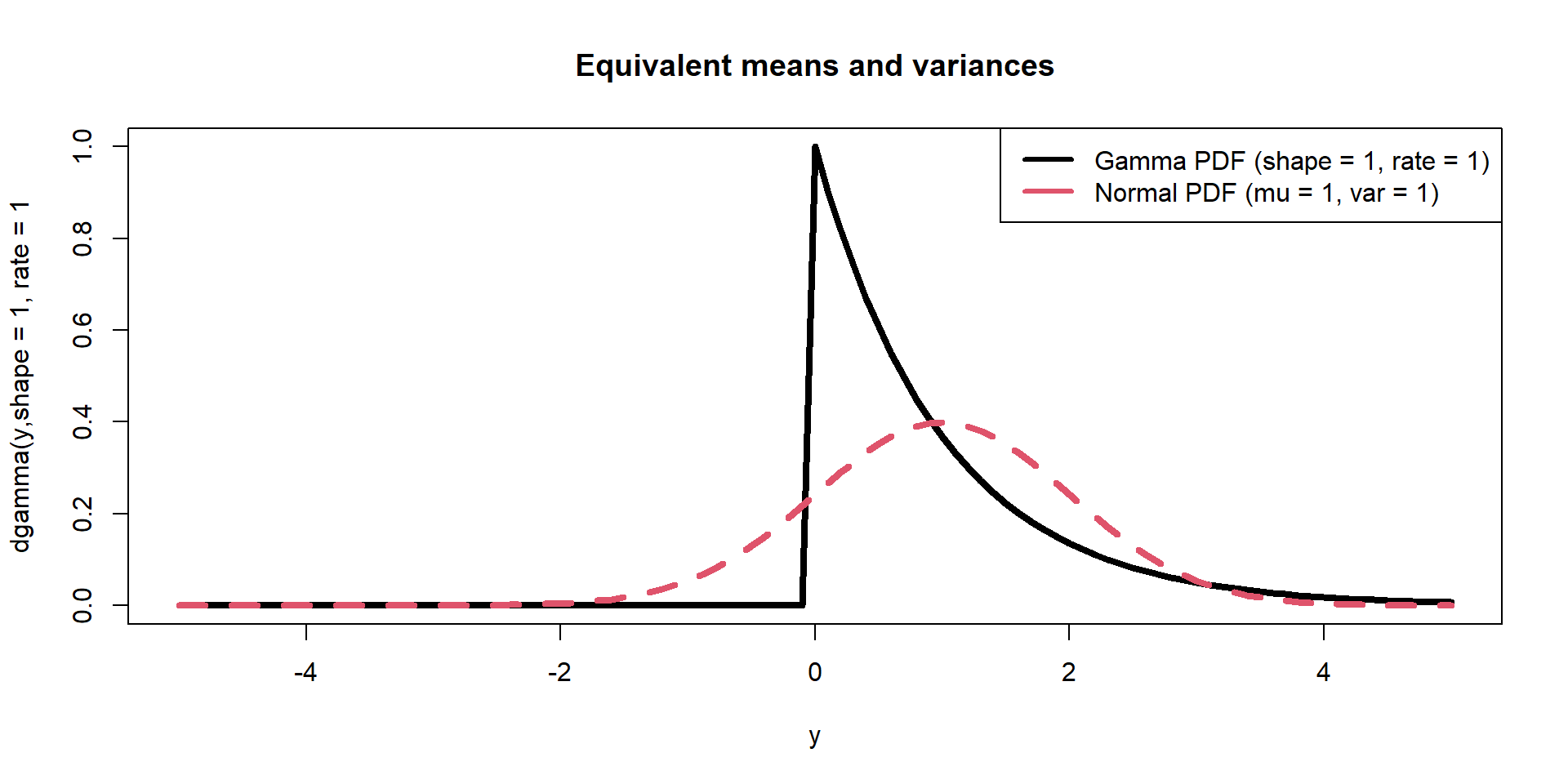
Data (e.g., \(y\)) are random variables that can be described by probability distributions with unknown parameters that (e.g., \(\theta\)) are fixed (scalars).
Bayesian Paradigm:
Data (e.g., \(y\)) are random variables that can be described by probability functions where the unknown parameters (e.g., \(\theta\)) are also random variables that have probability functions that describe them.
Random Variables
\[
\begin{align*}
y =& \text{ event/outcome} \\
f(y|\boldsymbol{\theta}) =& [y|\boldsymbol{\theta}]= \text{ process governing the value of } y \\
\boldsymbol{\theta} =& \text{ parameters} \\
\end{align*}
\]
\(f()\) or [ ] is conveying a function (math).
It is called a PDF when \(y\) is continuous and a PMF when \(y\) is discrete.
PDF: probability density function
PMF: probability mass function
Functions
We commonly use deterministic functions (indicated by non-italic letter); e.g., log(), exp(). Output is always the same with the same input. \[
\hspace{-12pt}\text{g} \\
x \Longrightarrow\fbox{DO STUFF
} \Longrightarrow \text{g}(x)
\]
\[
\hspace{-14pt}\text{g} \\
x \Longrightarrow\fbox{+7
} \Longrightarrow \text{g}(x)
\]
\[
\text{g}(x) = x + 7
\]
Random Variables
Probability: Interested in \(y\), the data, and the probability function that “generates” the data. \[
\begin{align*}
y \leftarrow& f(y|\boldsymbol{\theta}) \\
\end{align*}
\]
Statistics: Interested in population characteristics of \(y\); i.e., the parameters,
\[
\begin{align*}
y \rightarrow& f(y|\boldsymbol{\theta}) \\
\end{align*}
\]
Probability Functions
Special functions with rules to guarantee our logic of probabilities are maintained.
Discrete RVs
\(y\) can only be a certain set of values.
\(y \in \{0,1\}\)
0 = dead, 1 = alive
\(y \in \{0,1, 2\}\)
0 = site unoccupied, 1 = site occupied w/o young, 2 = site occupied with young
\(y \in \{0, 1, 2, ..., 15\}\)
count of pups in a litter; max could by physiological constraint
These sets are called the sample space (\(\Omega\)) or the support of the RV.
PMF
\[
f(y) = P(Y=y)
\]
Data has two outcomes (0 = dead, 1 = alive)
\(y \in \{0,1\}\)
There are two probabilities
\(f(0) = P(Y=0)\)
\(f(1) = P(Y=1)\)
Axiom 1: The probability of an event is greater than or equal to zero and less than or equal to 1.
\[
0 \leq f(y) \leq 1
\] Example,
\(f(0) = 0.1\)
\(f(1) = 0.9\)
Axiom 2: The sum of the probabilities of all possible values (sample space) is one.
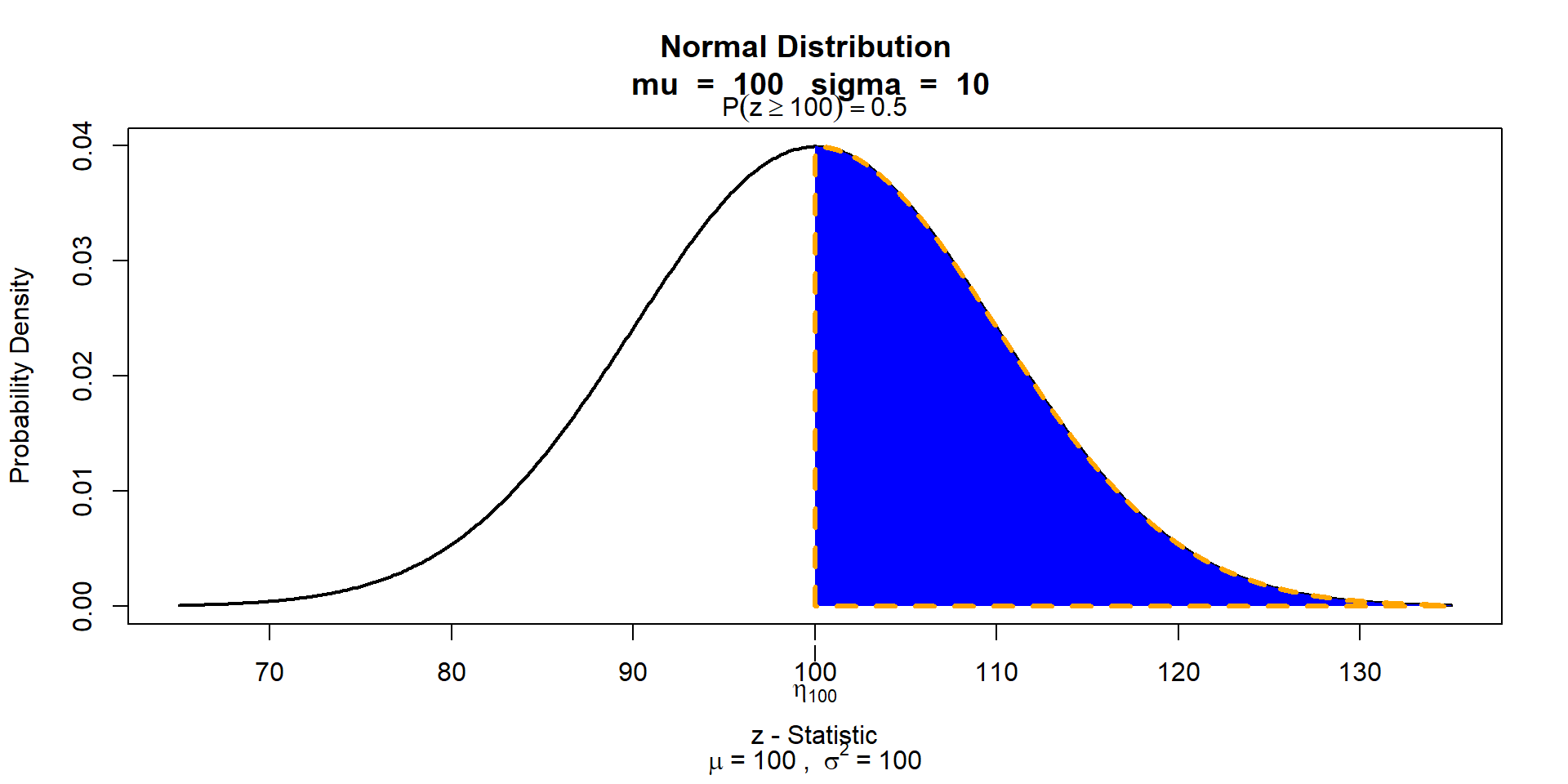
Read this as “the integral of the probability density function between 120 and infinity (on the left-hand side) is equal to the probability that the outcome of the random variable is between 120 and infinity (on the right-hand side)”.