\(\textbf{y}\) = vector of home range sizes of coyotes \(\beta_0\) = intercept \(\beta_1\) = effect diff. of HR size for urban coyotes \(\textbf{x}\) = indicator of HR in urban (1) or not in urban (0) \(\sigma^2\) = uncertainty / unknown variability
\(\beta_1\) is negative and statistically clearly different1 than zero
Prediction
Definition
The expected outcome from a hypothesis. If agrees with data, it would support the hypothesis or at least not reject it.
Example 1
Okay: Coyote home ranges are smaller in urban areas compared to non-urban areas
Example 2
Better: Coyote home ranges in urban areas with high available food resources is smaller than coyote home ranges in urban areas with less available food resources and smaller than coyotes living in non-urban areas
"It is of course desirable to work with manageable models which maximize generality, realism, and precision toward the overlapping but not identical goals of understanding, predicting, and modifying nature. But this cannot be done."
inference relies on randomly assigning some units to be in the sample (e.g., random sampling).
Design-Based
the values themselves are held to be fixed, whereas the sampling process is random.
Design-Based
Key Strengths: the population of interest is often defined (e.g., grid area); does not relying on stochastic models representing the structure of the data for reliable inference
Key Weaknesses: limited in application; still requires models to accommodate observational processes, such as detection probability
Design-Based
\(\textbf{Y}\) = [\(y_1\),…,\(y_N\)]
This means something different:
\(\textbf{Y}\) = (\(y_1\),…,\(y_N\))
(stuff) is exclusive of end points
[stuff] is inclusive of end points
Design-Based
\(\textbf{Y}\) = [\(y_1\),…,\(y_N\)]
The mean is \(\bar{Y} = \sum_{i=1}^N Y_i / N\) and the sample mean is \(\hat{\bar{y}} = \sum_{i=1}^n y_i / n\)
The population mean describes ….?
\(\textbf{y}\) is a random vector that has \(n\) random variables. One sample of 4 cells.
Wikipedia: A random variable (also called ‘random quantity’ or ‘stochastic variable’) is a mathematical formalization of a quantity or object which depends on random events.
We observe samples from the domain or population or sampling frame.
Samples are observed with some probability.
Statistic
\(\hat{\bar{y}}\) is a ‘statistic’ (# computed from a sample) and is also a random variable
statistics have a sampling distribution, describing the probability associated to observing different values of the statistic
“a statistical model describing how observations on population units are thought to have been generated from a super‐population with potentially infinitely many observations for each unit;”Williams and Brown, 2019
“The analysis need not account for sampling randomization, because the sample is considered fixed. However, the unit values are considered random.”Williams and Brown, 2019
Model-Based
BUT….
when linking ‘unit values’ in a model, we need to account for their dependence.
Randomization allows us to make conditional independence claims among data in our sample, thus the model is simpler.
\(P(y_{2}|y_{1}) = P(y_{2})\)
Model-Based
Key Strengths: Very flexible. Modeling is magic.
Key Weaknesses: 1) Can be difficult to assess assumptions and 2) sampling frame is not always clear and thus the population you are infering to is not entirely clear
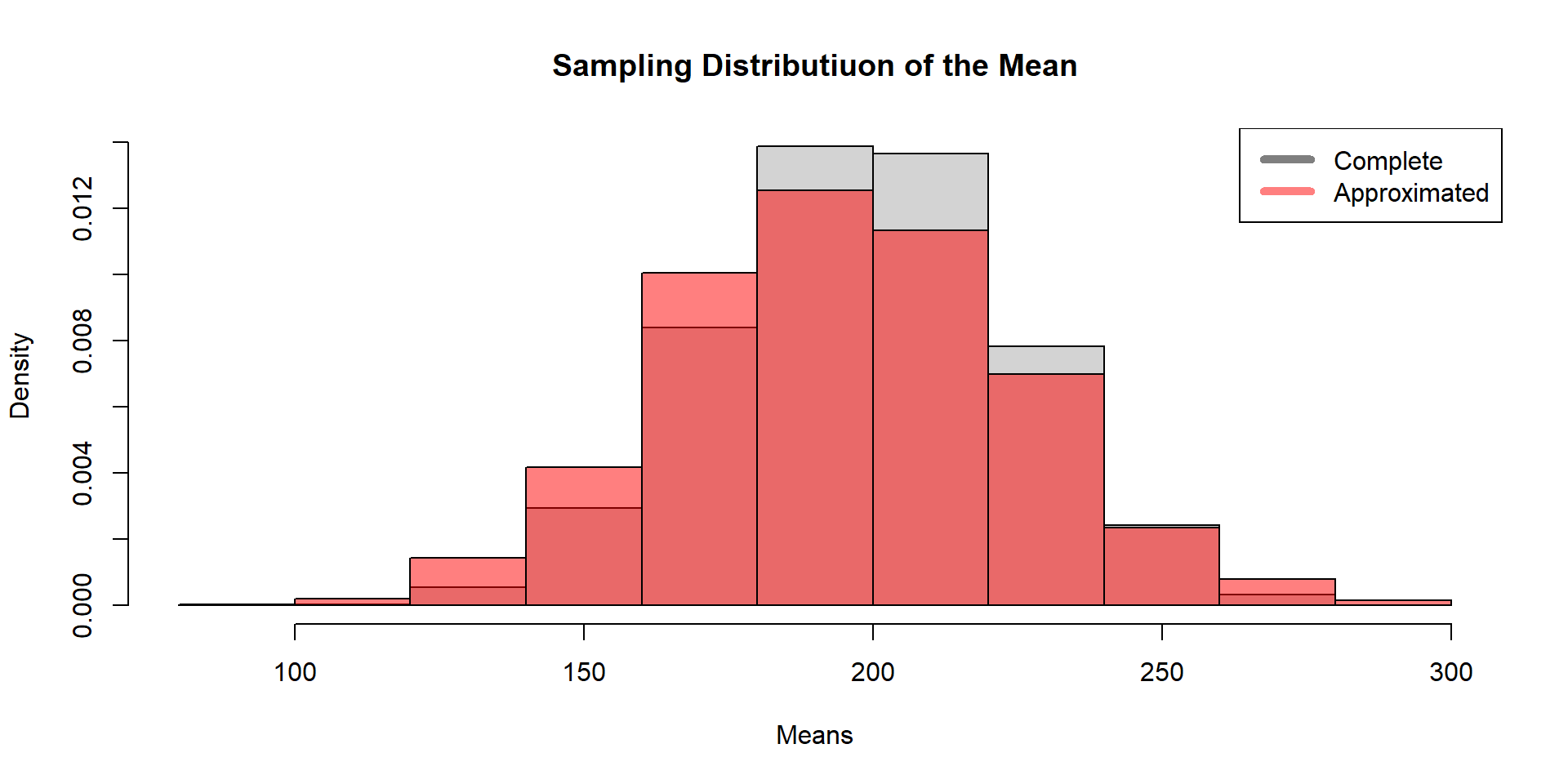
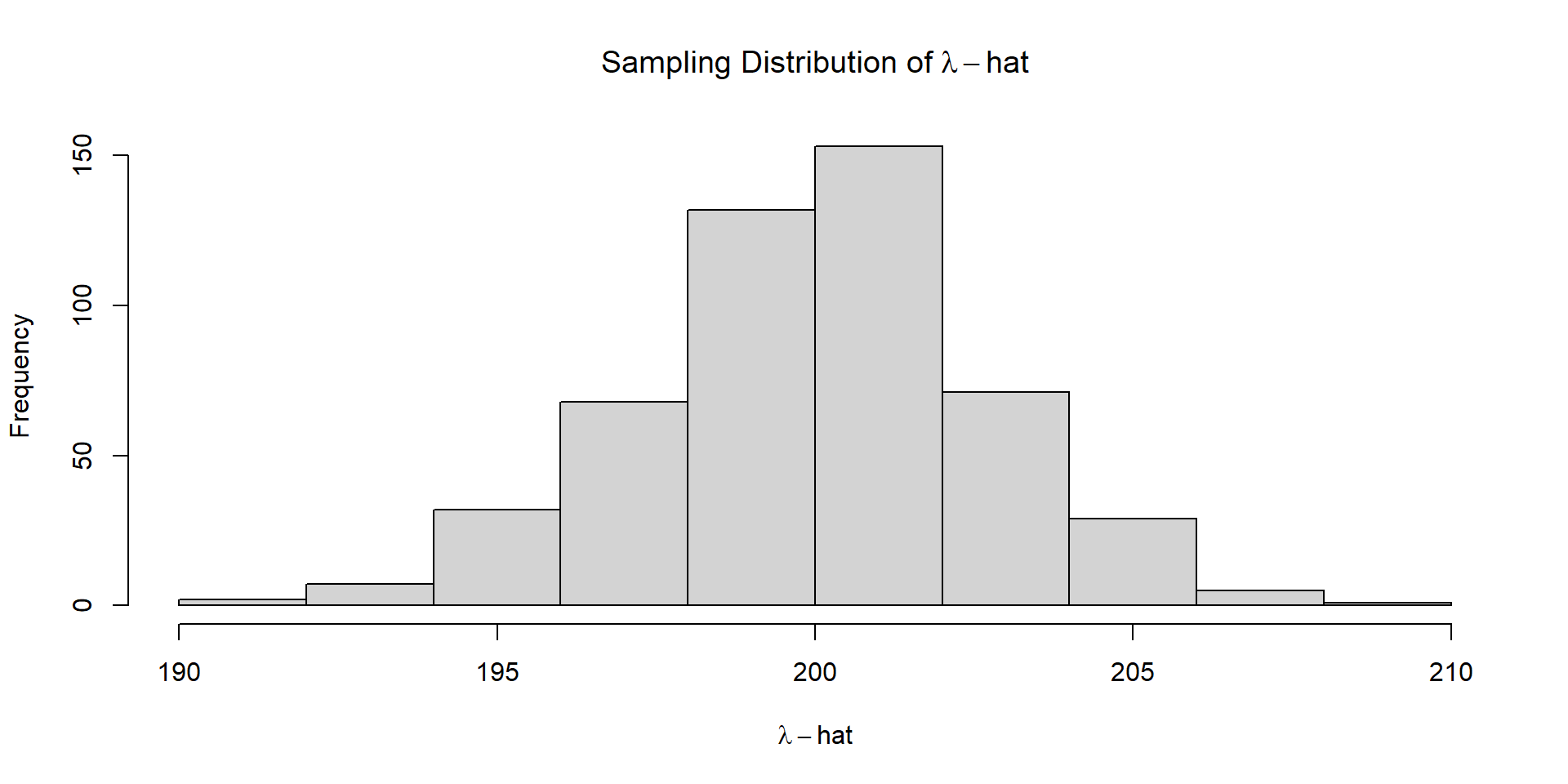
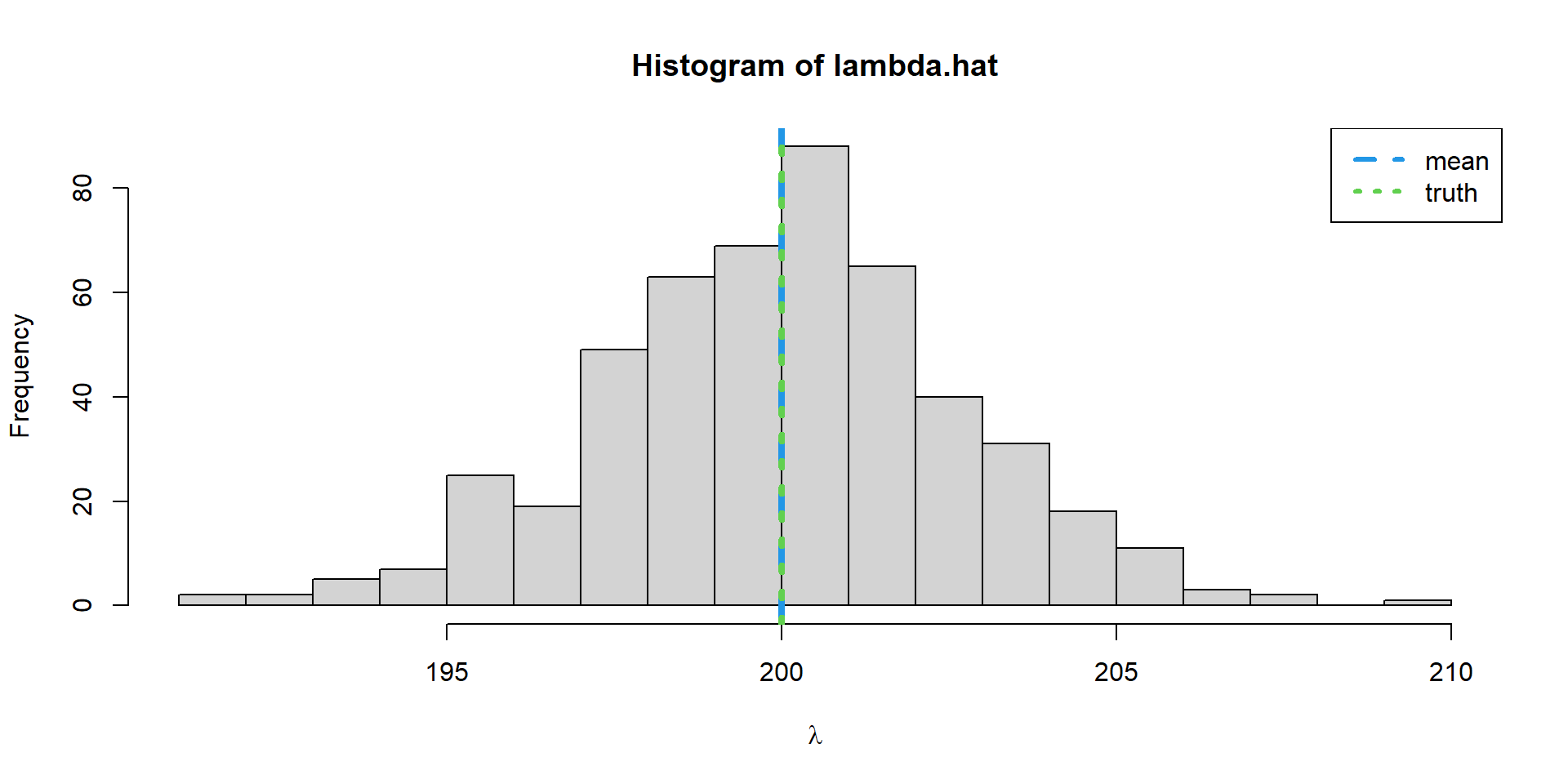
What is the probability that we will observe a mean within 5% of the truth?
We can calculate this using Monte Carlo integration
diff =0.025*lambda diff
[1] 5
lower = lambda-diff upper = lambda+diff index =which(lambda.hat>=lower & lambda.hat <= upper)#Probability of getting a mean within 5% of the truthlength(index)/n.sim
[1] 0.934
Take-Aways
1.Study Objectives, Hypotheses, and Predictions
2.Big Data and Sampling
3.Inference and Prediction
4. Model-Based vs Design-Based Inference
Lab
Objectives
Introduce R Markdown
Use simulation and design-based sampling to investigate bias and precision
Lab Setup
Let’s add some more reality in our work while using design-based sampling in R.
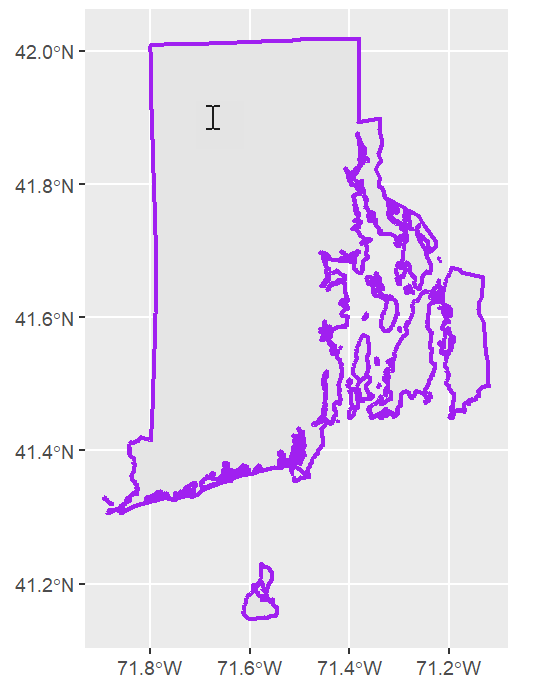
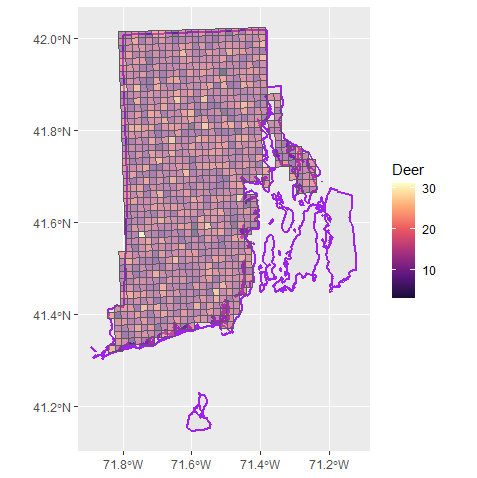
Objective: Evaluate sample size trade-offs for estimating white-tailed deer abundance throughout Rhode Island.
Methodology: Count deer in 1 sq. mile cells using FLIR technology attached to a helicopter.
Lab Setup
Steps to consider
Sampling Frame
all of RI or some subset
Lab Setup
Steps to consider
“Truth”
how many deer per cell; how variable
Lab Setup
Steps to consider
Sampling Process
how to pick each cell
Lab Setup
Steps to consider
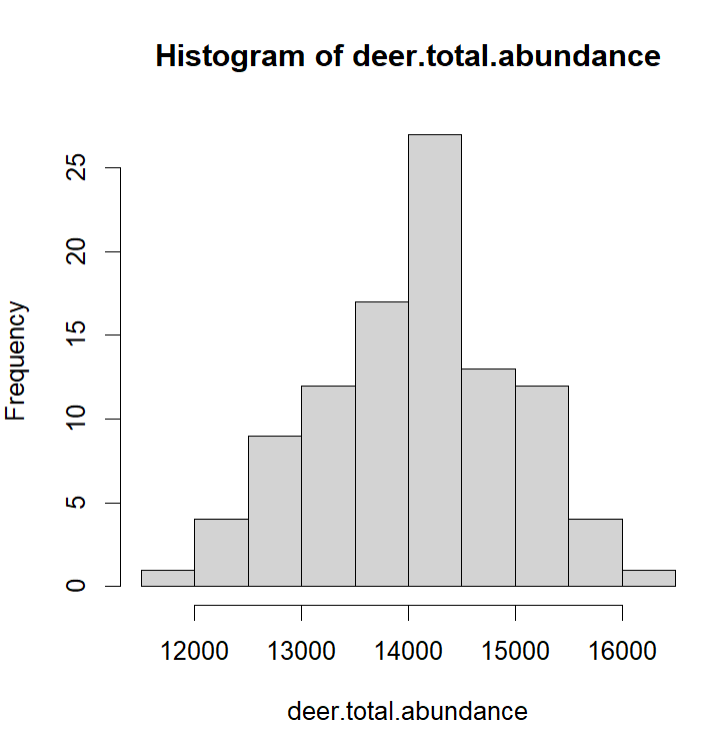
Estimation Process
estimate total deer population from the sample
Criteria to Evaluate
use sampling distribution of deer abundance estimate or some other statistic