library(pwr)# Wish to test a difference b/w groups 1 and 2# Want to know if there is a difference in means#Difference in Means effect.size <- Group1.Mean-Group2.Mean#Group st. dev group.sd <-sqrt(mean(c(Group1.SD^2,Group2.SD^2)))#Mean difference divided by group stdev#How does the numerator and denominator influence this number? d <- effect.size/group.sd
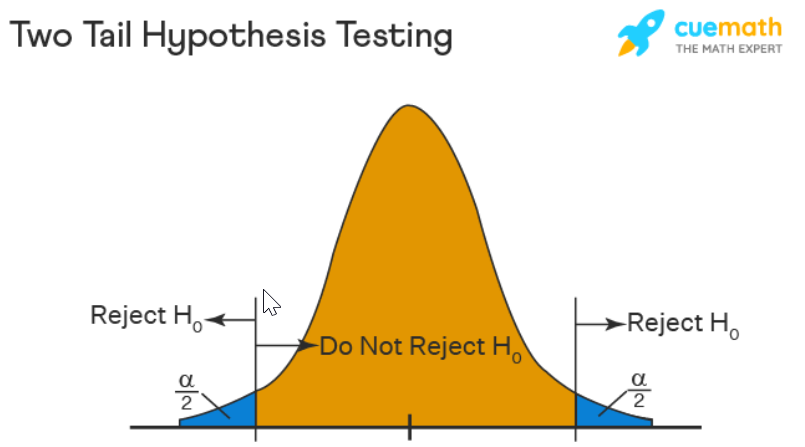
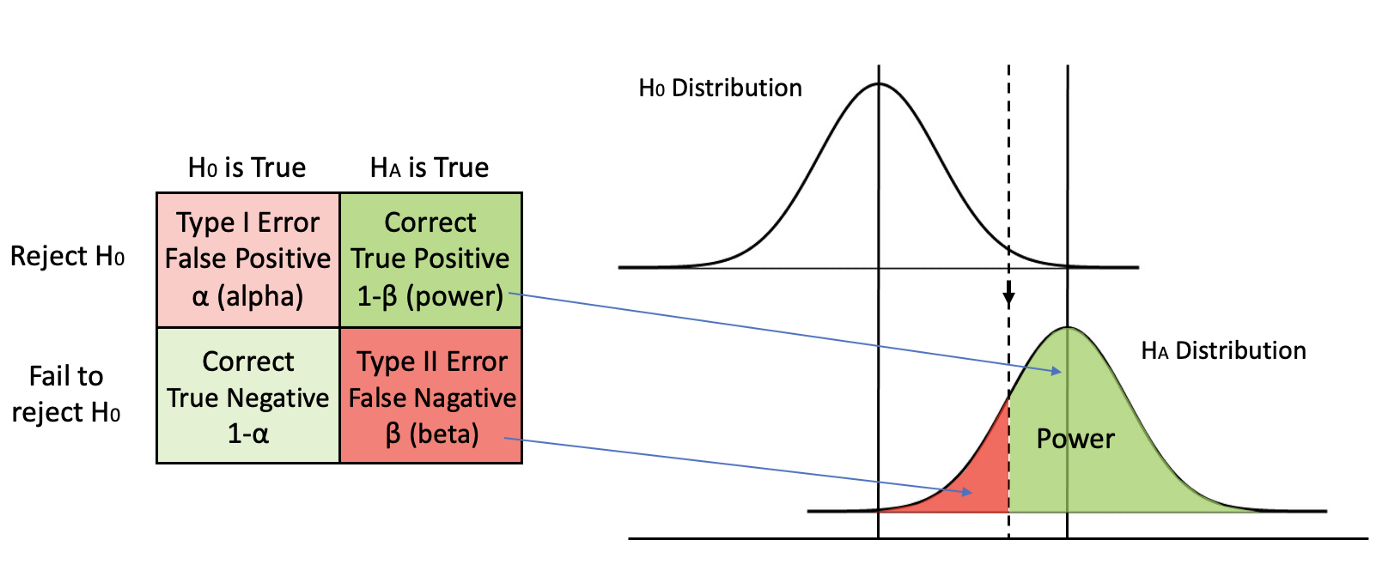
Case Study
power =0.8out =pwr.t.test(d=d,power=power,type="two.sample",alternative="two.sided")#Sample Size Needed for each Groupout$n
[1] 16.71472
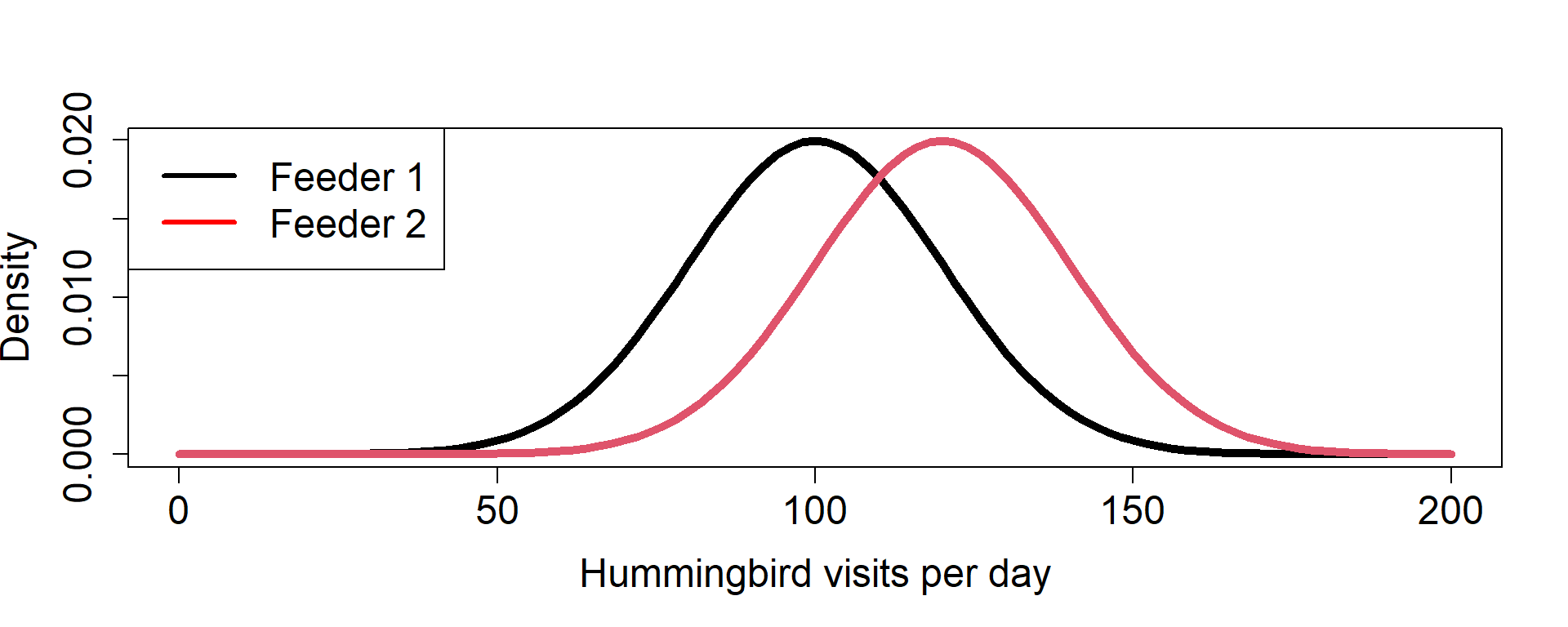
Assuming Independence b/w feeders How do we design our sampling to ensure this?
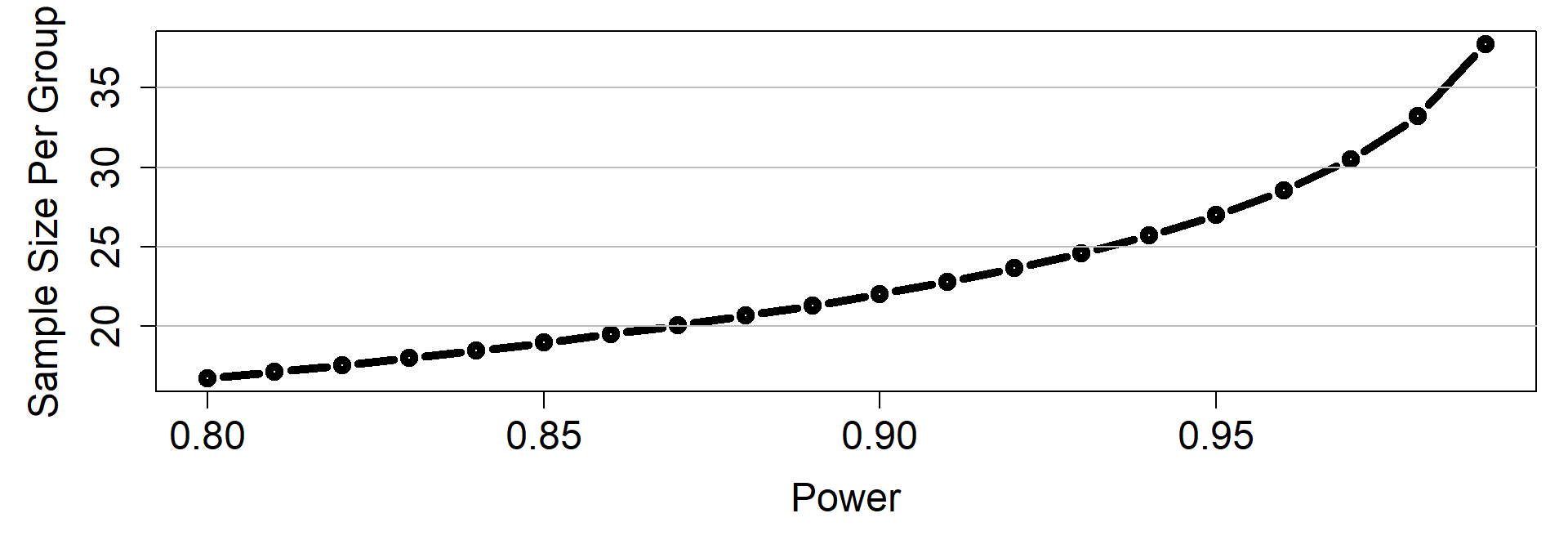
Tradeoff (Power vs N)
Let’s consider multiple levels of power
power =matrix(seq(0.8,0.99,by=0.01))my.func =function(x){ pwr.t.test(d=d,power=x,type="two.sample",alternative="two.sided" )$n}out=apply(power,1, FUN=my.func)
# Allow group 1 to vary Group1.Mean <-seq(10,110,by=5)#THIS IS THE SAME Group1.SD <-20 Group2.Mean <-120 Group2.SD <-20 group.sd <-sqrt(mean(Group1.SD^2,Group2.SD^2))# Variable effect.size effect.size <- Group1.Mean-Group2.Mean d <- effect.size/group.sd#setup combinations of d and power power =seq(0.8,0.99,by=0.01) power.d =expand.grid(power,d) power.d$Var1 =as.numeric(power.d$Var1)
#make new function and use mapplymy.func =function(x,x2){ pwr.t.test(d=x2,power=x,type="two.sample",alternative="two.sided" )$n}# mapply function out=mapply(power.d$Var1,power.d$Var2, FUN=my.func)# unstandardized the effect size back to difference of means power.d$Var2=power.d$Var2*group.sd out2=cbind(power.d,out)colnames(out2)=c("power","d","n")