The Big Data Paradox

“era of big data” - what does this mean for our field?
Boyd et al. 2023

- \(\sigma_Y\) is the population standard deviation
- \(f = n/N\); sampling rate
“when \(\rho(R,Y) >0\): larger values of Y are more likely to be in the sample than in the population and vice versa. Where \(\rho(R,Y) =0\), this term cancels the others and there is no [systematic] error”.
Back to Boyd et al. 2023
 - \(f = n/N\)
- \(f = n/N\)
- When \(\rho_{R,G}\) deviates even slightly from 0, the relative effective sample size (\(n_{eff}/n\)) decreases with the true population size, N.(See Meng 2018; Figure 2)
Implication: When \(N\) is large, your relative ESS (\(n_{eff}/n\)) is small; your data are worthless.
“In biodiversity monitoring, N is typically very large, so this reduction can be substantial.”
Back to Boyd et al. 2023
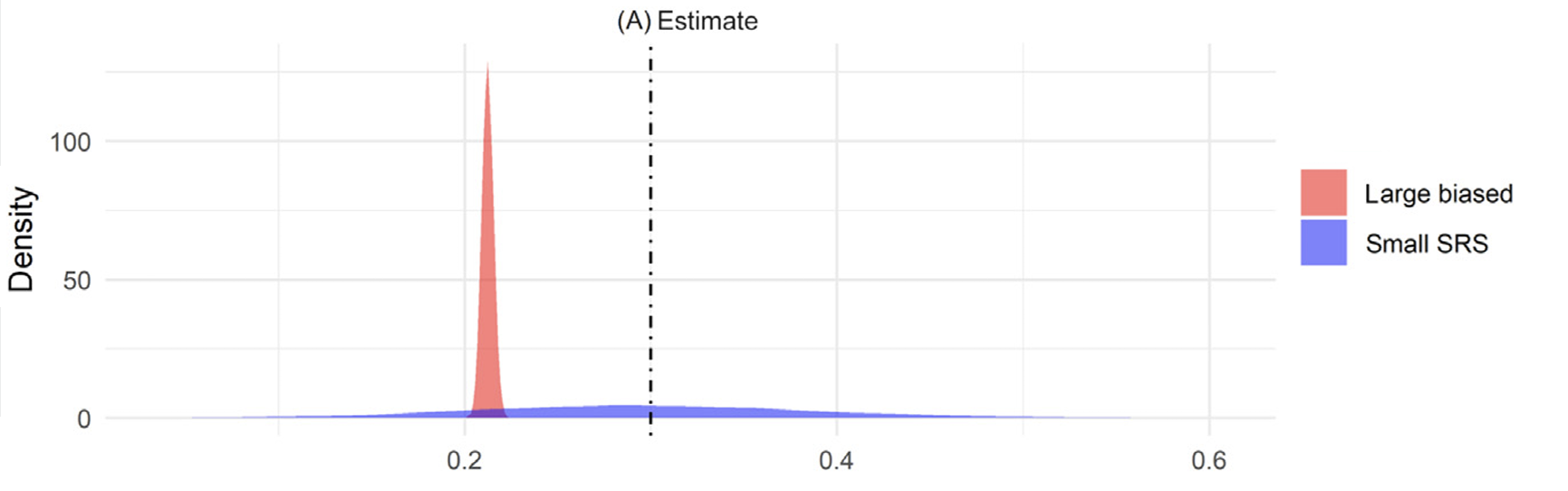
- ‘large biased’ is \(\rho_{R,G} = -0.058\), \(n = 1000\)
- MSE is the same
- 95% CI’s include the truth 0% of the time for ‘Large Biased’
Back to Boyd et al. 2023
Take home: Large biased data –> highly biased and highly precise estimates